
What is Supervised Learning?
Supervised learning is a type of machine learning where a computer is taught using examples of real data and “known” data, where the teacher knows the correct answer and teaches someone else. Learning can take any form, from simple human feedback or input to a more complex model that predicts the outcome of future events.
Supervised learning requires two things:
- Training data: The data is used to train the model.
- Training Algorithm: Transforming training data into a model that can predict new data.
It is one of the most popular forms of machine learning because it requires less effort from the programmer to train the algorithm than other techniques such as reinforcement learning.
In supervised learning, the algorithm being taught is given a set of inputs and corresponding outputs. The algorithm looks at these examples and tries to create rules to match inputs and outputs. The more examples are presented, the better he can learn this mapping. Once training is complete, the supervised learning algorithm can make predictions about new inputs that were not present in the original training.
There are two types of problems solved by supervised learning: classification and regression. Classification is the process of placing an object into one or more classes based on its characteristics, while regression is the estimation of the value of a variable based on other variables or inputs.
Top 10 interview questions for supervised learning.
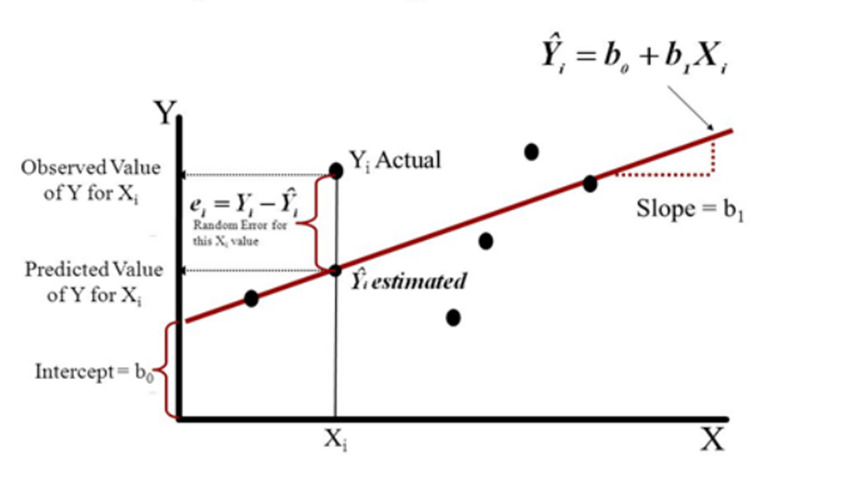
1. What is Linear regression?
Linear Regression is a technique that can be used to find the linear relationship between two variables.
Linear Regression is a technique in statistics and machine learning. It is used for finding the linear relationship between two variables. The algorithm estimates the slope and intercept of the line that best fits a set of points.
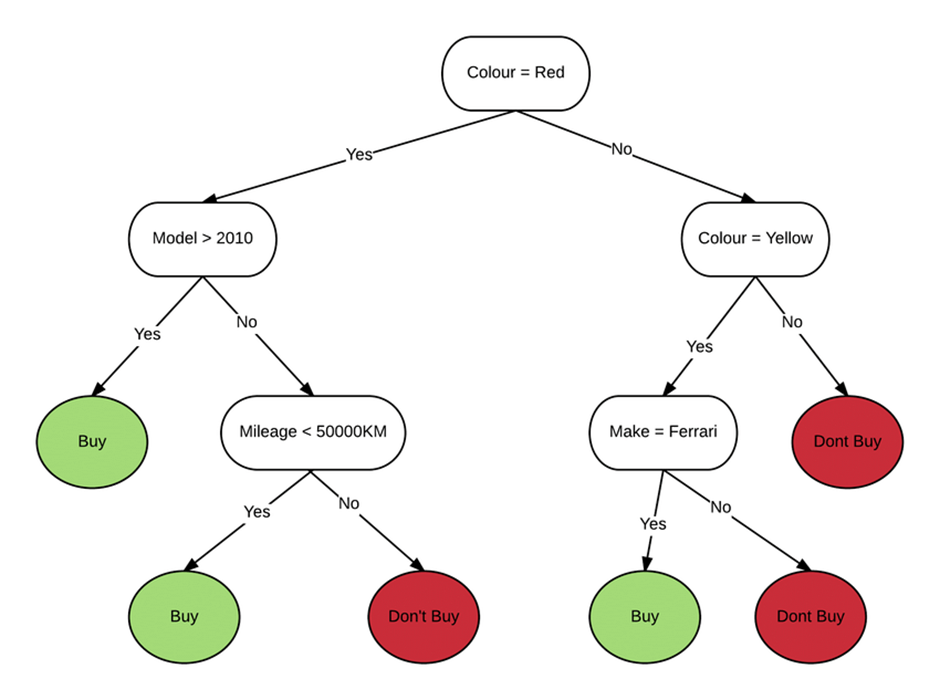
2. What are Decision Trees?
Decision trees are a type of AI algorithm that is used to classify data. A decision tree is made up of a sequence of “if-then” statements, each representing a test on an attribute of the data.
The decision tree starts with the root node, which splits the data into two branches: one for those who meet the criterion and one for those who don’t. The next node takes the data from both branches and splits it again into two more branches according to another criterion. This process continues until there is only one branch left containing all the data that meets all of the criteria specified by the nodes in its path.
Decision trees can be used for tasks such as classification, regression, clustering and feature selection.
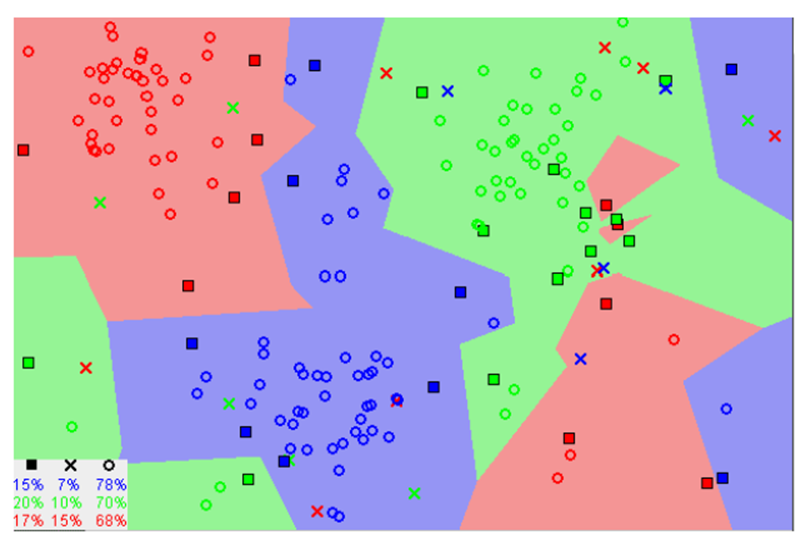
3. What are the two types of problems solved by Supervised Learning?
Supervised Learning is a type of machine learning algorithm that uses data to train a model. The two types of problems solved by supervised learning are classification and regression.
Classification: Classification is the process of assigning an object to one or more classes based on its features. classification algorithms are linear classifiers, support vector machines (SVM), decision trees, k-nearest neighbor, and random forest.
Regression: Regression is the process of estimating the value of a variable given other variables or inputs. Linear regression, logistical regression, and polynomial regression are significant algorithms that are used for regression analysis.
4. Why Naive Bayes is called Naive?
The Naive Bayes algorithm is called “naive” because it assumes that all the features are independent of one another. It is naive to think that just because two features are not related in the training data, they will not be related in the general population. However, this assumption often leads to good predictions.
Naïve Bayes is a classification algorithm for statistical learning that uses Bayes’ theorem with strong (naïve) independence assumptions between predictors.
5. What is the difference between KNN and K-means Clustering?
K-means clustering is a method of cluster analysis that is used to determine how many clusters should be created. K-means clustering starts with an arbitrary number of points, called a priori groups, and assigns each point to the nearest group. The algorithm then iteratively reassigns each point to the group which minimizes the sum of squared distances from that point to the points in its group.
KNN is a machine learning algorithm for supervised learning in which training data is used to construct a function that predicts an output value based on input values. KNN can be applied using different distance metrics, such as Euclidean distance or Manhattan distance.
6. What is k-Nearest Neighbors algorithm?
The k-Nearest Neighbors algorithm is a class of machine learning algorithms. It is used for classification and regression analysis.
The k-Nearest Neighbors algorithm classifies an input as belonging to one of the classes by looking at its distance from the training data points in the feature space. The algorithm recursively finds the nearest neighbor for each point until it reaches a stopping point, or until there are no more points left to classify.
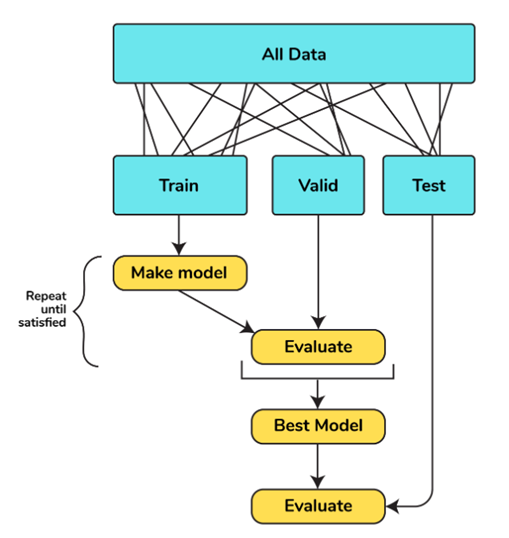
7. What is Cross-Validation and why is it important in supervised learning?
Cross-validation is a technique to estimate the accuracy of a model by using a subset of the data that was used to train it.
The reason why cross validation is important in supervised learning is because it helps us estimate how accurate our model will be for future predictions.
8. How is Gradient Boosting used to improve Supervised Learning?
Gradient Boosting is a machine learning algorithm that can be used to improve the accuracy of supervised learning. It works by applying many weak learners to the data and then combining their predictions. The predictions from these learners are not individually very accurate, but when combined together, they create a model that is more accurate than any individual learner.
9. What are some disadvantages of Supervised Learning?
One of the disadvantages of supervised learning is that it requires a lot of data. This can be an issue in fields where there is not much data available or where the data is not labeled.
Another disadvantage of supervised learning is that it doesn’t generalize well to new datasets. This means that if you have a dataset with a different distribution, then your algorithm will be unable to generalize to it and make accurate predictions.
10. What is the difference between Gradient Boosting and Adaptive Boosting?
Gradient Boosting is a machine learning technique that optimizes the loss function. The difference between Gradient Boosting and Adaptive Boosting is that Gradient Boosting uses gradient descent to optimize the loss function, while Adaptive Boosting uses adaptive stepsize control.
Adaptive boosting is a machine learning technique that optimizes the loss function. It does this by calculating an optimal step size for each iteration of gradient descent. This technique does not require any parameter tuning, and its performance varies depending on how many iterations are used for training.
