
Alexnet Architecture Explained | Introduction to Alexnet Architecture
The introduction of AlexNet in 2012 has changed the image recognition field. Thousands of researchers and entrepreneurs were able to approach artificial intelligence in a different manner by using this deep neural network that Alex Krizhevsky, Ilya Sutskever and Geoffrey Hinton created together. Considering how strictly quantitative and limited computer vision technology was: barely classifying and analyzing images accurately as a meaningful approach; AlexNet changed everything. Every pixel within a photo holds context and meaning that the past models couldn’t even recognize.
AlexNet
AlexNet was one of the most important milestone in deep learning. Its many deep layers and complicated computational tricks went on to allow this particular network to deliver levels of accuracy in image recognition not previously thought possible.With millions of pictures of cats and dogs render to a significantly higher complexity, AlexNet quickly broke through the visual analysis limitations, aiding with better medical imaging, autonomous vehicles, and face recognition.
Alex Krizhevsky developed AlexNet, a groundbreaking deep learning architecture that built upon and refined the basic convolutional neural network. During his research, Krizhevsky worked closely with Geoffrey E. Hinton, a renowned expert in deep learning, who guided him through the development of this innovative neural network design.
Alex Krizhevsky used the AlexNet model on ILSVRC2012 and emerged the winner, with a top-5 error rate of, 15.3% which was 10.8 percentage points better than the second placed team.
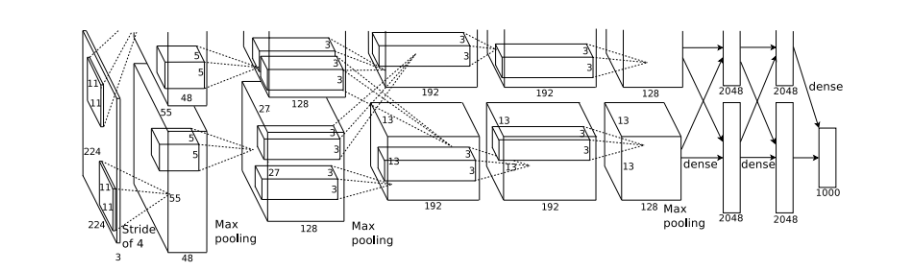
Architecture of AlexNet
- In summary, the trackers following the AlexNet architecture comprises in total of eight layers.
- The first five layers are all convolution layers.
- The sizes of the convolution filters for the convolutional layers of the net are 11 × 11 , 5 × 5 , 3 × 3 , 3 × 3 and 3 × 3.
- some of the convolutional layers are accompanied by max-pooling layers that are especially valuable for dimensionality reduction within spatial operations.
- Researchers widely use the Rectified Linear Unit (ReLU) activation function in neural network because it provides higher accuracy compared to sigmoid and tanh functions.
- Three fully connected layers follow the convolutional layers in the network’s architecture.
- Network parameters are tunable at runtime to maximize network accuracy based on training results to optimize performance.
- AlexNet supports transfer learning by using pre-trained weights from the ImageNet corpus to achieve high-performance results.
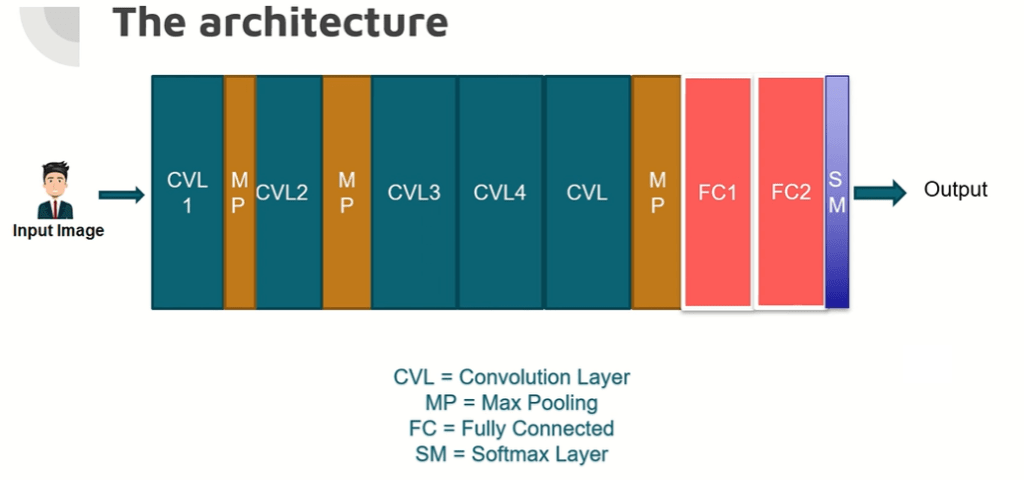
AlexNet Architecture
Point 1 – Convolutional Neural Network (CNN): AlexNet is one of the deep Convolutional Neural Network (CNN) models specially developed for the image classification tasks. CNNs are specially designed to solve image recognition problems, where convolutional layer is used to Infer the features of an image based on a hierarchical structure.
Point 2 – Architecture: AlexNet architecture has been composed of eight layers, five of which are the layers of convolution and three of which are the layers of fully connected layers. The convolutional layers aim to find out the important features from images, on the other hand the fully connected layers classify based on those features.
Point 3 – ReLU Activation: After each convolutional and fully connected layer the Rectified Linear Unit (ReLU) activation functions are used. ReLU also adds the non-linearity into the model allowing the network learn complex structure of the data.
Point 4 – Max Pooling: Instead, max pooling layers are used with some convolution layers to reduce spatial features which contain necessary features. This downsampling process helps in achieving reduced computation and also seems to solve the problem of overfitting.
Point 5 – Local Response Normalization: To improve generalization, Local Response Normalization (LRN) is used to normalize a neuron’s output compared with its neighbors. This causes a lateral inhibition kind of effect; thus making the network more tolerant if the input data information changes.
Point 6 – Dropout: AlexNet uses dropout where a neuron is removed from the neural network during dropout with a probability of 0.5. A neuron that is dropped does not make any contribution to either forward or backward propagation. The acquired weight parameters are therefore more reliable and less prone to overfitting.
Point 7 – Batch Normalization: Batch Normalization is used in training networks to normalize in the outputs of the activated layer within a given mini-batch. It helps bring about stability and speed up the training process of gaining more higher learning rates architecture.
Point 8 – Softmax Activation: The final layer to fully connected, the softmax function to turn AlexNet’s output to probabilities of each class. This gives the possibility of the forthcoming classes based on the input image.
Point 9 – Training and Optimization: AlexNet’s training process is carried out under Stochastic Gradient Decent with Momentum Optimization Process. Learning rate is changed during training and data is augmented in order to mean diversification of training set.
Point 10 – ImageNet Competition: AlexNet have proven successful when the was used to compete in the ImageNet Large Scale Visual Recognition Challenge ILSVRC in 2012. With the help of better performance, it brought deep learning and CNNs into focus for image classification.
Conclusion
AlexNet in early 2012 signified a revolution in the deep learning and computer vision field. It introduced new architecture, it had depth, and used new methods such as ReLU activation, dropout, and data augmentation at the time of proposal making it a benchmark for CNN models. AlexNet is known to have delivered excellent performances and even presented substantial contribution to the ImageNet competition and by doing so it opened up a better horizon for further development of this field to come up with new applications of artificial intelligence.
(adsbygoogle = window.adsbygoogle || []).push({});If you found this article helpful and insightful, I would greatly appreciate your support. You can show your appreciation by clicking on the button below. Thank you for taking the time to read this article.
kofiwidget2.init(‘Support Me on Ko-fi’, ‘#29abe0’, ‘G2G7MNHBM’);kofiwidget2.draw();Popular Posts
- From Zero to Hero: The Ultimate PyTorch Tutorial for Machine Learning Enthusiasts
- Day 3: Deep Learning vs. Machine Learning: Key Differences Explained
- Retrieving Dictionary Keys and Values in Python
- Day 2: 14 Types of Neural Networks and their Applications
