
Difference between Leaky ReLU and ReLU activation function?
What is an Activation Function?
An activation function is a critical component in neural networks. It determines a neuron’s output after the neuron processes its inputs by computing a weighted sum. The activation function decides whether the neuron should be activated or not, introducing nonlinearity to the model. This nonlinearity enables the model to learn and represent more complex patterns beyond linear relationships.
Without activation functions, a neural network would behave like a linear regression model, regardless of the number of layers. Activation functions help neural networks learn from complex data, such as images, speech, or text, and are essential for solving both simple and complex problems.
Leaky ReLU
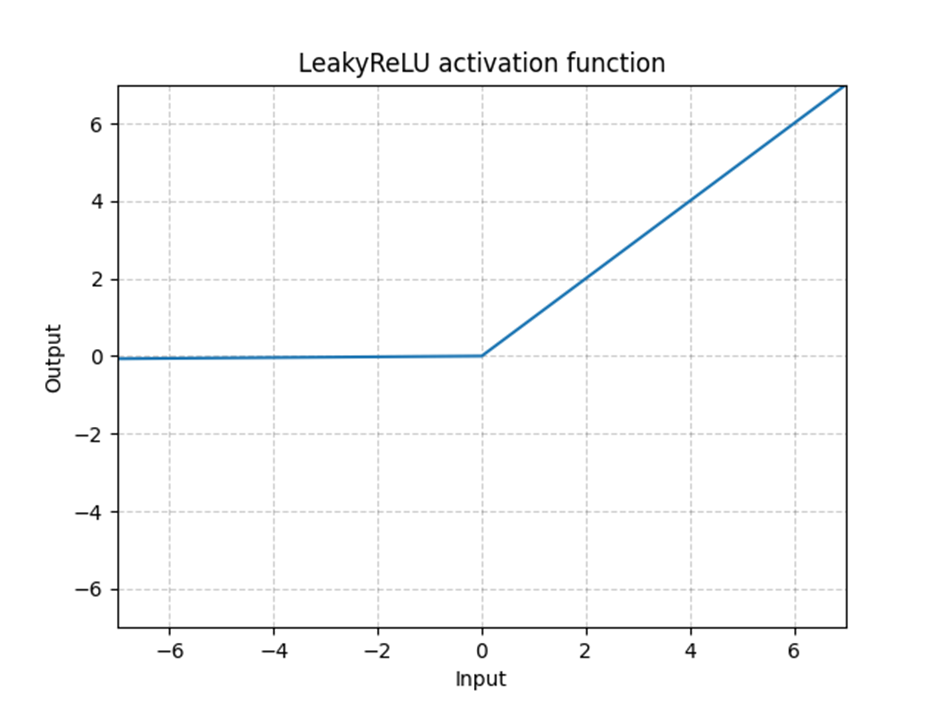
Leaky ReLU modifies the traditional ReLU by allowing a small, non-zero gradient for negative inputs. This prevents neurons from dying and keeps them active.
Mathematical Definition:
For an input x:
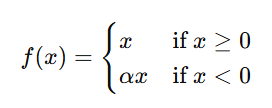
Here, α is a small constant (e.g., 0.01).
Example:
- If the input is 1.2, the output is 1.2.
- If the input is −2, the output is −2 × α.
For α = 0.01, the output becomes −2 × 0.01 = −0.02.
Advantages of Leaky ReLU:
- It ensures that neurons do not die by returning a small fraction of the negative input as output.
- The small non-zero gradient allows neurons to remain active and capable of learning during backpropagation.
- Leaky ReLU is particularly useful in deeper networks where neurons frequently receive negative inputs.
it is a variant of the ReLU activation function. It uses leaky values to avoid dividing by zero when the input value is negative, which can happen with standard ReLU when training neural networks with gradient descent.
Also Read: What is ReLU and Sigmoid activation function
Sigmoid Activation Function in Detail Explained
ReLU (Rectified Linear Unit)
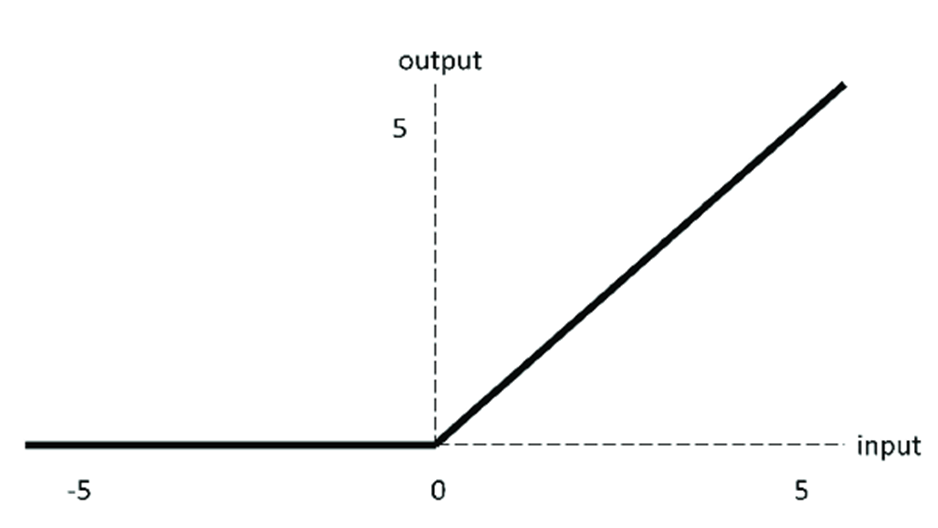
ReLU is the most widely used activation function in modern neural networks. It works by activating or deactivating neurons, setting negative input values to zero while leaving positive values unchanged.
Mathematical Definition:
For any input x, the output of ReLU is:
f(x) = max(0, x)
The output ranges from 0 to ∞.
Advantages of ReLU:
- It is computationally efficient, as it involves minimal operations.
- Hidden layers in most modern deep learning architectures commonly use ReLU, where the logits or raw outputs of neurons pass through the ReLU function.
Drawbacks of ReLU:
- Dying ReLU Problem:
ReLU sets all negative input values to zero. If a neuron consistently receives negative inputs, it may get stuck in an inactive state, outputting zero. This means the neuron stops learning and becomes useless.Once a neuron enters this “dead” state, it no longer updates its weights during backpropagation, as the gradient becomes zero. This can cause parts of the network to underperform, especially in deeper networks or when the learning rate is too high.
Solutions to the Dying ReLU Problem:
- Using a Smaller Learning Rate:
Reducing the learning rate can help prevent drastic weight updates, minimizing the chance of neuron death. - Leaky ReLU:
A more standard solution is to use Leaky ReLU, which introduces a small negative slope for negative inputs.
ReLUs aren’t perfect, however, these disadvantages are compensated for by the fact that a ReLU can be applied in different parts of the network and is continuous at zero.
Conclusion
ReLU and Leaky ReLU are important activation functions in deep learning. While ReLU is simple and computationally efficient, it can suffer from the dying ReLU problem. Leaky ReLU provides a solution by introducing a small negative slope, keeping neurons alive even for negative inputs. Understanding these activation functions is crucial for building efficient and robust neural networks.
