
LeNet-5 Architecture Explained | Introduction to LeNet-5 Architecture
LeNet-5 is a compact neural network comprising fundamental components of deep learning convolutional layers, pooling layers, and fully connected layers. It serves as a foundational model for other deep learning architectures. Let’s talk about the LeNet-5 and enhance our understanding of convolutional and pooling layers through practical examples.
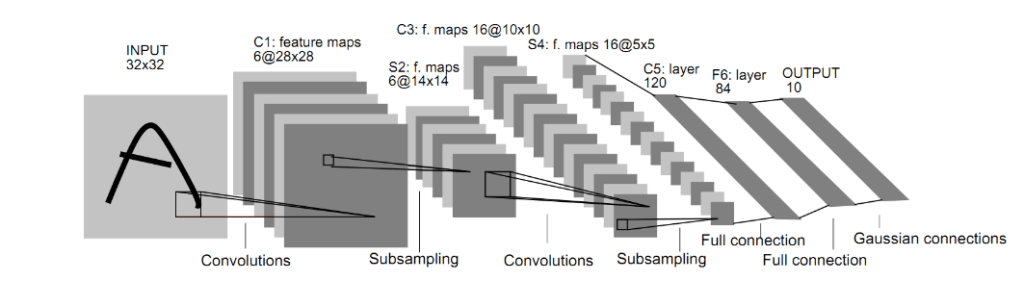
Introduction to LeNet-5
LeNet-5 consists of seven layers, excluding the input layer. Each layer involves trainable parameters. The core modules are:
- Convolutional Layer
- Pooling Layer
- Fully Connected Layer
This network is pivotal in recognizing handwritten characters and leveraging image structural features.
Layer-by-Layer Explanation
Input Layer
The initial layer processes the data input. The input image dimensions are normalized to 32 x 32 pixels. However, this layer isn’t considered part of LeNet-5’s core architecture.
C1 Layer – Convolutional Layer
- Input Image: 32 x 32 pixels
- Convolution Kernel Size: 5 x 5
- Number of Kernels: 6
- Output Feature Map Size: 28 x 28 (due to the convolution operation)
- Neurons: 28 x 28 x 6
- Trainable Parameters: (5 x 5 + 1) x 6 (25 weight parameters + 1 bias parameter per filter, 6 filters in total)
- Connections: (5 x 5 + 1) x 6 x 28 x 28 = 122,304
S2 Layer – Pooling Layer
- Input: 28 x 28 feature maps
- Pooling Area: 2 x 2
- Pooling Method: Summation with trainable weight and offset, followed by sigmoid activation
- Number of Feature Maps: 6
- Output Feature Map Size: 14 x 14 (due to downsampling)
- Neurons: 14 x 14 x 6
- Trainable Parameters: 2 x 6 (weight sum + offset)
- Connections: (2 x 2 + 1) x 6 x 14 x 14 = 5,880
C3 Layer – Convolutional Layer
- Input: Combinations of 6 or more feature maps from S2
- Convolution Kernel Size: 5 x 5
- Number of Kernels: 16
- Output Feature Map Size: 10 x 10 (due to convolution)
- Neurons: 10 x 10 x 16
- Trainable Parameters: 6 x (3 x 5 x 5 + 1) + 6 x (4 x 5 x 5 + 1) + 3 x (4 x 5 x 5 + 1) + 1 x (6 x 5 x 5 + 1) = 1,516
- Connections: 10 x 10 x 1,516 = 151,600
S4 Layer – Pooling Layer
- Input: 10 x 10 feature maps
- Pooling Area: 2 x 2
- Pooling Method: Summation with trainable weight and offset, followed by sigmoid activation
- Number of Feature Maps: 16
- Output Feature Map Size: 5 x 5 (due to downsampling)
- Neurons: 5 x 5 x 16 = 400
- Trainable Parameters: 2 x 16
- Connections: (2 x 2 + 1) x 16 x 5 x 5 = 2,000
C5 Layer – Convolutional Layer
- Input: All 16 feature maps from S4
- Convolution Kernel Size: 5 x 5
- Number of Kernels: 120
- Output Feature Map Size: 1 x 1 (due to convolution)
- Trainable Parameters: 120 x (16 x 5 x 5 + 1) = 48,120
- Connections: 48,120
F6 Layer – Fully Connected Layer
- Input: 120-dimensional vector from C5
- Calculation: Dot product with weight vector and offset, followed by sigmoid activation
- Nodes: 84
- Trainable Parameters: 84 x (120 + 1) = 10,164
Output Layer – Fully Connected Layer
- Nodes: 10 (representing digits 0 to 9)
- Radial Basis Function (RBF) network connection
- Trainable Parameters and Connections: 84 x 10 = 840
Conclusion
LeNet-5 is a concise neural network used for recognizing handwritten characters. Its convolutional and pooling layers capitalize on image structure. The convolutional layers have fewer parameters due to local connections and shared weights, which enhances their efficiency.
Popular Posts
- From Zero to Hero: The Ultimate PyTorch Tutorial for Machine Learning Enthusiasts
- Day 3: Deep Learning vs. Machine Learning: Key Differences Explained
- Retrieving Dictionary Keys and Values in Python
- Day 2: 14 Types of Neural Networks and their Applications