
What is the difference between LSTM and GRU?
Introduction to LSTM (Long Short-Term Memory)
Imagine you’re at a murder mystery dinner. At the very beginning, the Lord of the Manor suddenly collapses, and your task is to figure out, who done it? It could be the maid or the butler. However, there’s a problem: your short-term memory is not working. You can’t recall any of the clues beyond the last 10 minutes. This makes your predictions no better than a random guess.
Now, imagine the opposite scenario, where you can remember every word of every conversation you’ve ever had. If someone asked you to summarize your partner’s wedding vows, you might struggle because of the sheer amount of information. It would be much easier if you could focus on just the memorable parts.
This is where Long Short-Term Memory (LSTM) comes into play. Abbreviated as LSTM, this neural network mechanism enables a model to retain necessary information (context) while forgetting irrelevant details.
Understanding LSTM through Sequences
To understand how LSTM works, let’s look at a sequence of letters. Predicting the next letter by viewing them individually can be challenging. For instance, if we see two “M”s in different contexts, they might be followed by different letters. However, analyzing the entire sequence reveals patterns, like recognizing the phrase, “My name is Martin.”
LSTMs excel at processing sequential data by establishing context over time, unlike basic models that struggle with long-term dependencies.
LSTM and Recurrent Neural Networks (RNNs)
LSTM is a specialized type of Recurrent Neural Network (RNN). Here’s how an RNN node works:
- Input and Output: Each node receives input, processes it, and generates an output.
- Recurrence: The output of a given step loops back as input for the next step.
For example, when processing the sentence, “My name,” an RNN does not need to go far back to understand the context. However, if it needs to process an hour-long conversation (e.g., a murder mystery dinner), RNNs face the long-term dependency problem. Over time, as more information accumulates, they struggle to retain useful context.
LSTMs solve this problem by introducing an internal state to the RNN node.
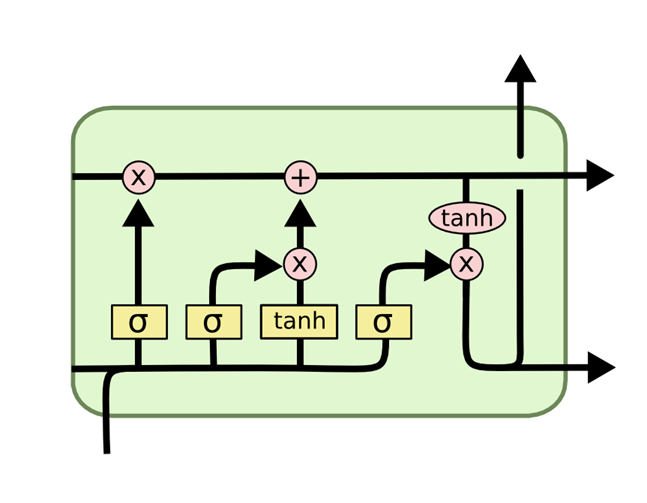
LSTM Internal Structure: The Gates
An LSTM cell has three critical components called gates, each performing specific tasks:
- Forget Gate: Determines what information to discard from the internal state.
- Input Gate: Decides what new information to add to the internal state.
- Output Gate: Selects which part of the internal state should be output at the current step.
These gates operate on a scale of 0 to 1:
- 0: Fully closed, blocking all data.
- 1: Fully open, allowing all data through.
This mechanism enables LSTMs to focus on contextually relevant information, ensuring efficient learning and predictions over long sequences.
Gated Recurrent Unit
The Gated Recurrent Unit (GRU) is a neural network architecture designed for sequence modeling tasks. GRUs are a variation of recurrent neural networks (RNNs) and are closely related to Long Short-Term Memory (LSTM) cells but with some key differences.
Overview of GRUs
The GRU architecture is a simplified version of the LSTM. While LSTMs include three gates (forget, input, and output), GRUs only have two gates: the reset gate and the update gate. This simplification makes GRUs computationally efficient while retaining the ability to model long-term dependencies.
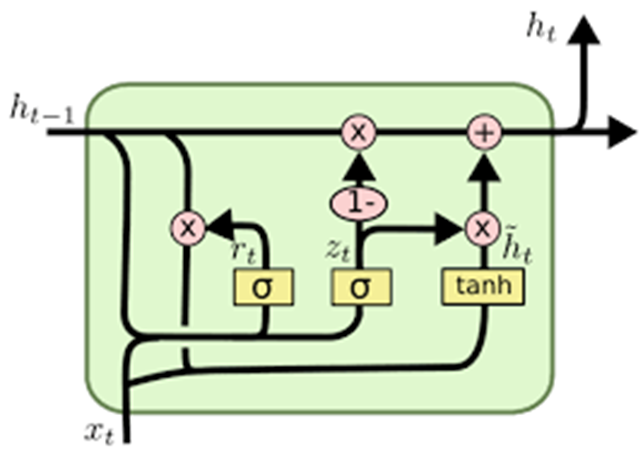
GRU Structure and Notations
The general structure of a GRU involves operations like sigmoid activation (denoted by σ), tanh activation (represented by φ), vector addition, and element-wise multiplication. A unique operation in GRUs is 1 − vector, where the output is computed by subtracting the input vector from one.
GRU Equations
The operations of GRUs are governed by a set of equations that dictate how information flows and transitions through the network.
- Reset Gate: The reset gate decides how much of the previous hidden state should be forgotten.
- Candidate Hidden State: The candidate hidden state computes the new information to be added at the current step.
- Update Gate: The update gate controls the blending of the previous hidden state and the candidate hidden state to produce the current hidden state.
- Final Hidden State:The final hidden state is computed by selecting information from both the previous hidden state and the candidate hidden state using the update gate.
Functionality and Mechanism
The GRU effectively decides:
- What to retain from the previous hidden state.
- What new information to add from the candidate hidden state.
The reset gate focuses on forgetting irrelevant information, while the update gate blends the past and current information based on their importance.
