
A Comprehensive Guide on Attention-Based RAG
The advanced model Attention-Based RAG (Retrieval-Augmented Generation) extends RAG principles through attention mechanisms to improve both retrieval precision and document synthesis. This method utilizes self-attention techniques together with cross-attention approaches to improve document selection and content synthesis thus generating more contextually appropriate responses. Extensive research is presented in this article through a deep analysis of Attention-Based RAG starting from its operational foundation while exploring implementation approaches including Python code examples together with visual explanations.

1. How Does Attention-Based RAG Work?
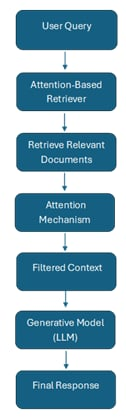
Transformer-based attention techniques in Attention-Based RAG improve retrieval processes while optimizing generation phases through optimized attention methods. It consists of two key stages:
a. Retrieval Stage:
Advanced attention mechanisms allow a retriever model to select important documents from a knowledge base. Self-attention layers inserted into Attention-Based RAG help enhance both document comparison scores and retrieval order. Self-attention layers within the retriever dynamically measures different document segments through attention techniques. Through document embedding multi-head attention processes it boosts contextual retrieval-Tion through transformer-based attention techniques.
Key Innovation:
- Uses self-attention layers in the retriever to weigh different document segments dynamically.
- Enhances contextual retrieval by incorporating multi-head attention on document embeddings.
b. Generation Stage:
A transformer-based generative model synthesizes responses using retrieved documents. Cross-attention mechanisms enhance contextual alignment between input queries and retrieved documents.
Key Innovation:
- Applies cross-attention to dynamically integrate retrieved context into the response generation process.
- Reduces hallucinations and improves factual consistency by aligning outputs with retrieved content. The combination of attention mechanisms into both retrieval systems and response-generating systems creates substantial improvements in the quality and coherence of answers produced by the model.
2. When and Why to Use Attention-Based RAG?
- Complex Query Scenarios: Attention-Based RAG functions effectively for applications that require detailed understanding together with context-aware responses including legal and medical fields.
- Multi-Document Reasoning: This system proves best suited for combining information from multiple different sources.
- Dynamic Knowledge Environments: Attention-Based RAG effectively processes datasets with ongoing updates to provide current responsive results.
Why Use Attention-Based RAG?
- Improved Relevance: The combination of self-attention in retrieval facilitates higher accuracy for document selection.
- Context-Aware Responses: Through the use of cross-attention technology the retrieved data merges efficiently with generated responses.
- Reduced Hallucination: The strategy to link generation with retrieved data results in fewer misleading or incorrect outputs.
Pros of Attention-Based RAG
1. Enhanced Context Awareness
Explanation: Within attention-based RAG platforms the attention mechanism works as a core element which enhances model capability for focused data attention to crucial query-relevant elements. By calculating weight values for different input sections the model produces dynamic decisions about which retrieved document parts hold the most importance.
Example: The legal assistant AI identifies essential case laws after assessing particular legal queries so responses reflect both accuracy and precision in context. The system produces superior outcomes for users by selecting only important legal case precedents from its search output.
Improved Answer Quality
Explanation: The cross-attention algorithm establishes strong correlations between information retrieval components and the model’s content generation process. The model increases response relevance and coherence by actively managing contextual focus until retrieved documents shape its final output.
Example: A medical AI systems enables users to obtain diagnostic assessments by analyzing similar case-reports when they present symptoms. The attention mechanism guarantees both correct information selection and proper alignment with the query to yield better diagnosis accuracy.
Robustness in Multi-Document Processing
Explanation: Rag-Based Attention enables the systematic integration of information throughout multiple sources which allows the model to pull knowledge points from various documents or data points. Through the attention mechanism the system ensures smooth information combined from diverse sources leading to unified whole systems.
Example: An AI system can combine key information from multiple journal articles supporting research questions through attention-based processing into coherent answers about complicated questions.
Cons of Attention-Based RAG
Higher Computational Cost
Explanation: All input data needs full processing by the attention mechanism to create weighted representations leading to elevated model complexity levels. These attention weights require extensive computations across numerous documents and tokens thereby producing costly models.
Challenge: The hardware requirements of Attention-Based RAG models extend to high-performance GPUs or TPUs that become challenges for systems operating with minimal computational capabilities. These models prove difficult to implement on mobile devices together with resource-limited environments.
Latency in Real-Time Applications
Explanation: The combination of retrieval phase with attention-based processing adds prolonged computation to queries that produce response delays. The performance capacity of these models produces context-sensitive results effectively but they fail to provide speedy delivery.
Challenge: Response speed remains a key requirement for instant applications that use chatbots or customer service artificial intelligence. The processing delays encountered during attention calculations exceed acceptable response times within situations requiring immediate feedback. When customers engage in live chat conversations significant delays create detrimental effects on their experience.
Complexity in Training and Fine-Tuning
Explanation: Attention-based RAG models excel after detailed tuning because this optimization step helps adjust their attention weighting system for various tasks. Earlier attention models required adjustment of numerous parameters in order to properly work through the attention mechanism during training processes. The implementation of transformer architectures needs both extensive training expertise and a large base of data to achieve targeted performance tasks.
Challenge: Deep knowledge of machine learning especially in transformer model complexity is essential for successful implementation of attention-based RAG systems. The precise level of expert knowledge may lack availability within all teams while improper training or lack of model fine-tuning can negatively impact performance quality.
4. Where to Use Attention-Based RAG?
Customer Support
- Efficiency: Through accurate knowledge retrieval and integration the response quality of chatbots improves.
Example: AI-driven customer support for banking services.
Healthcare
- Decision Support: Real-time medical literature insights help doctors make better clinical decisions through support services.
Example: AI-powered clinical decision support systems.
Education
- Adaptive Learning: The system brings personalized education to students by delivering the most appropriate knowledge materials.
Example: AI tutors dynamically generating learning materials.
Legal Research
- Case Law Analysis: Attorneys can use the tool to locate necessary legal decisions in an expedited manner.
Example: The retrieval process of court judgments through AI legal assistants operates for precise case needs.
5. Implementation of Attention-Based RAG
The implementation of Attention-Based RAG in Python is introduced through a systematic approach in this section.
Step 1: Define the Knowledge Base
The embedding-based retrieval system serves as storage for documents.
Step 2: Build an Attention-Based Retriever
A transformer model equipped with a self-attention-based ranking system functions in this design.
Step 3: Integrate Attention-Based Memory Module
Frequent requests and responses should be cached as an essential component of this framework which adopts context-sensitive mechanisms.
Step 4: Connect to the Generator
The output emerges from a transformer model which uses generative methods alongside cross-attention computation.
6. Python Implementation
# Import necessary libraries from transformers import AutoTokenizer, AutoModelForSeq2SeqLM import faiss import numpy as np
Step 1: Create a knowledge base with embeddings
documents = [
"The sun rises in the east.",
"Water freezes at 0 degrees Celsius.",
"Python is widely used in data science.",
"The capital of Germany is Berlin.",
"Neural networks are a subset of machine learning."
]
def create_embeddings(docs):
embeddings = np.random.rand(len(docs), 128) # Simulated embeddings with higher dimensions
return embeddings
embeddings = create_embeddings(documents)
Step 2: Build FAISS Index
index = faiss.IndexFlatL2(128)
index.add(embeddings)
def retrieve(query, k=3):
query_embedding = np.random.rand(1, 128) # Placeholder embedding for query
distances, indices = index.search(query_embedding, k)
return [documents[i] for i in indices[0]]
Step 3: Setup attention-based caching
cache = {}
def retrieve_with_cache(query):
if query in cache:
return cache[query]
retrieved_docs = retrieve(query)
cache[query] = retrieved_docs
return retrieved_docs
Step 4: Generate response using cross-attention model
tokenizer = AutoTokenizer.from_pretrained("facebook/bart-large-cnn")
generator = AutoModelForSeq2SeqLM.from_pretrained("facebook/bart-large-cnn")
def generate_response(query, context):
input_text = query + "\n" + "\n".join(context)
inputs = tokenizer.encode(input_text, return_tensors="pt", max_length=512, truncation=True)
outputs = generator.generate(inputs, max_length=50, num_beams=5, early_stopping=True)
return tokenizer.decode(outputs[0], skip_special_tokens=True)
Example query
query = "What is The capital city of Germany?"
retrieved_docs = retrieve_with_cache(query)
response = generate_response(query, retrieved_docs)
print("Retrieved Documents:", retrieved_docs)
print("Generated Response:", response)
Conclusion
The Attention-Based RAG system uses attention mechanisms to create an advanced retrieval-augmented generation framework which achieves better relevance and coherence. Large-scale difficulties with computation and complexity remain as challenges yet the system demonstrates strong advantages in process scalability and high-precision response generation across multiple domains.
