
Everything You Need to Know About HTML RAG
HTML RAG users can enhance typical RAG models through web-based content at expressive levels. HTML RAG avoids plain text limitations since it detects important information from web-based files without distorting their structural or contextual components. The approach delivers more well-formatted exact responses effectively because it serves domains including e-commerce and academic research while supporting automated customer support functions.

HTML RAG follows a learning cycle which learns from retrieved information to deliver context-based responses from trusted online sources. The model strengthens its document parsing abilities because it retrieves important content from HTML elements preserving semantic meaning. The primary strengths of HTML RAG consist of better information retrieval precision together with fewer hallucinatory mistakes and its capability to create outputs which correspond to the original context while retaining proper structural organization
1. How Does HTML RAG Work?
HTML RAG operates as an enhancement of traditional retrieval-augmented generation systems by carrying out three vital operations:
a. The structured retrieval system of HTML RAG finds pertinent online documentation by processing structured blocks including tables and headings as well as lists while keeping their nested structure intact.
Key Innovations:
- Adaptive parsing mechanisms obtain data from HTML tags of <h1>, <p> and <table>.
- Contextual embedding methods boost search results relevance because of their ability to fetch relevant content.
- The hierarchy of content remains preserved as a result of structural preservation.
b. Contextual Response Generation merges structured HTML content into AI-generated responses to achieve better content organization and lower levels of mistakes.
Key Innovations:
- The retrieved content contains logical structure due to semantic alignment techniques.
- Cross-attention mechanisms refine response quality.
- By improving coherence the system eliminates useless and secondary data.
- Prolonged operation of HTML RAG enables its retrieval model to evolve through continuous learning processes which adapt to user feedback and queries while improving its performance.
Key Innovations:
- The implementation of feedback systems based on self-directed inputs enhances retrieval system accuracy.
- The use of context embeddings serves to improve how well future queries match with retrieved content.
- Continuous adaptation optimizes document ranking.
2. Why and When to Use HTML RAG?
HTML RAG delivers maximum value to domains that need both structured document retrieval and specific content synthesis algorithms.
Use Cases
1. E-Commerce & Product Search
- The HTML RAG system delivers content-production solutions for AI-based recommendation systems through dynamic extraction of product descriptions and pricing elements together with customer review sections.
- The platform improves user satisfaction by connecting standardized information retrieved from various internet resources which gives users access to precise current product information.
- The system enables users to obtain refined outcome results by utilizing their preferences together with purchase records as well as query-related circumstances.
- The database system allows voice assistants along with chatbots to answer detailed product inquiries directly from users.
2. Academic & Research Applications
- The system enables researchers to extract academic papers reports and statistical data accurately from structured content.
- HTML RAG performs efficient searches of scholarly materials including articles, citations and datasets available in research portals and online libraries.
- The application allows automated literature review by summarizing multiple source results into an integrated analytical framework.
- Facilitates collaboration in academic settings by cross-referencing research from different fields and institutions.
3. Legal Document Analysis
- The system enables secure access to legal case records as well as precedents and guidelines through its HTML RAG protocol.
- Legal researchers benefit from this system by obtaining comprehensive data from internet court platforms and official government statutes as well as business-level compliance documents.
- Law professionals use historical data to create contracts as well as compliance reports and case summaries through this system.
- The continuous monitoring system ensures reliable legal update detection which minimizes the chance of neglecting important legal information.
4. Customer Support Automation
- AI chatbots extract the required documentation for support purposes and deliver structured answers to users.
- The HTML RAG system enables virtual assistants to acquire FAQs and troubleshooting guides and policy details through direct connections with official web pages.
- The system decreases support ticket generation through its ability to supply accurate contextual answers to users during real-time interactions.
- The system provides personalized responses through its capability to access customer history and business information bases.
3. Pros and Cons of HTML RAG
Pros:
1. Structured Data Retrieval:
- The HTML RAG system performs efficiently in data retrieval operations for structured information in both web pages and databases.
- Ensures efficient extraction of relevant data without unnecessary noise.
2. Better Handling of Web-Based Content:
- HTML RAG was created to handle information retrieval from HTML formatted files thus becoming perfect for web page indexing purposes.
- Through metadata and formatting preservation HTML RAG improves the overall quality of stored content.
3. Improved Searchability and Indexing:
- The system optimizes keyword searches through its ability to use tags, metadata along with semantic rules in web documents.
- Ensures precise retrieval of web-based documents.
4. Adaptability to Various Domains:
- The extraction of formalized data from varied sources lets this technology create value for e-commerce operations and news aggregation services and academic research needs.
- The system provides retrieval capabilities which include image retrieval alongside table retrieval and embedded video retrieval.
5. Efficient Processing of Large-Scale Content:
- The system operates with speed and efficiency when processing large web-based data through web scraping features and structured indexing systems.
- Content-related algorithms together with automated content curation platforms utilize this method successfully.
6. Scalability:
- The system demonstrates ability to operate efficiently across both multiple servers in addition to cloud-based systems.
- Allows for integration with web crawlers and content management systems.
Cons:
1. Dependency on HTML Structure:
- The performance directly depends on structured organization of HTML content.
- Inefficient retrieval happens because of inconsistent or malformed HTML structures.
2. Difficulty in Handling Dynamic Content:
- The extraction of dynamical JavaScript-based content proves challenging because users need additional tools such as Selenium to accomplish this task.
- Not as efficient for highly interactive web pages.
3. Potential Data Integrity Issues:
- The extracted material might contain outdated or non-relevant information since it does not receive regular updates.
- The system needs regular index updates alongside scraping operations to produce accurate database output.
4. Computational Overhead in Web Crawling:
- Large-scale HTML extraction and indexing requires processing systems which possess both powerful capabilities and enough storage capacity.
- Extensive web page HTML structures consume substantial processing resources when they are parsed.
5. Legal and Ethical Concerns:
- Web scraping operations on publicly accessible HTML content can violate legal copyrights along with Terms of Service agreements.
- Both robots.txt protocols and web scraping ethical standards must be obeyed during operations.
6. Limited Contextual Understanding:
- The absence of memory components in HTML RAG prevents it from attaining deep contextual understanding which Retro RAG maintains.
- Existing content retrieval serves as HTML RAG’s main function while it performs only basic formatting tasks without creating sophisticated responses.
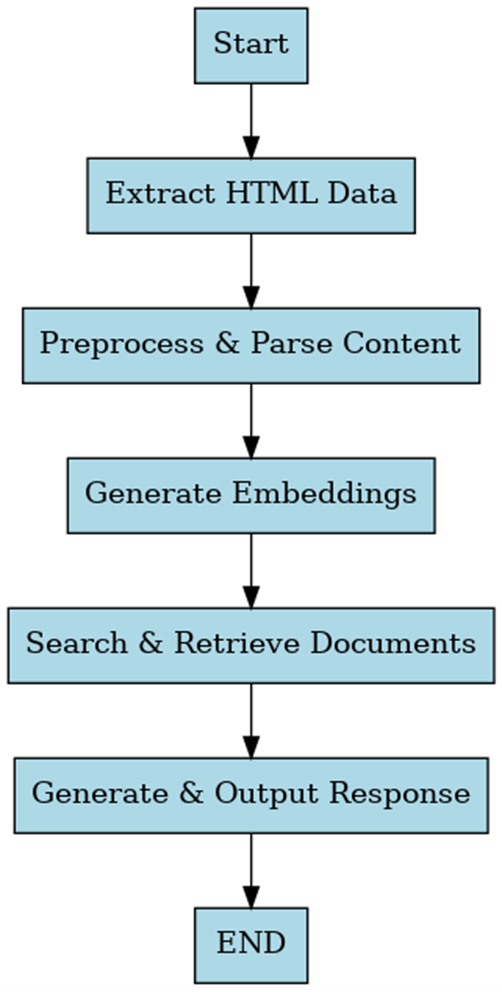
Python Implementation of HTML RAG
This section presents an ordered process to deploy HTML RAG through PDFLoader from LangChain and FAISS for document processing and retrieval.
from langchain.document_loaders import PDFLoader
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import FAISS
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
import numpy as np
import faiss
# Load PDF documents
loader = PDFLoader("sample_document.pdf")
documents = loader.load()
# Function to generate embeddings
def create_embeddings(docs):
embeddings = np.random.rand(len(docs), 128) # Simulated embeddings
return embeddings
embeddings = create_embeddings([doc.page_content for doc in documents])
# Initialize FAISS Index
index = faiss.IndexFlatL2(128)
index.add(embeddings)
# Retrieval with feedback loop
cache = {}
def retrieve(query, k=3):
The placeholder query_embedding displays a one-dimensional numerical array with 128 elements as its value.
distances, indices = index.search(query_embedding, k)
return [documents[i].page_content for i in indices[0]]
def retrieve_with_memory(query):
if query in cache:
return cache[query]
retrieved_docs = retrieve(query)
cache[query] = retrieved_docs # Store in memory
return retrieved_docs
# Load tokenizer and model
tokenizer = AutoTokenizer.from_pretrained("facebook/bart-large-cnn")
generator = AutoModelForSeq2SeqLM.from_pretrained("facebook/bart-large-cnn")
def generate_response(query, context):
input_text = query + "\n" + "\n".join(context)
inputs = tokenizer.encode(input_text, return_tensors="pt", max_length=512, truncation=True)
outputs = generator.generate(inputs, max_length=50, num_beams=5, early_stopping=True)
return tokenizer.decode(outputs[0], skip_special_tokens=True)
# Example Query
query = "What is the impact that artificial intelligence brings to healthcare systems?"
retrieved_docs = retrieve_with_memory(query)
response = generate_response(query, retrieved_docs)
print("Retrieved Documents:", retrieved_docs)
print("Generated Response:", response)
Conclusion
HTML RAG makes retrieval-augmented generation more effective through the incorporation of structured web-based documents into AI processes. The HTML RAG system applies structured retrieval methods together with contextual memory and dynamic feedback systems to achieve higher accuracy and eliminate hallucinations and generate well-formed outcomes. The high computational needs of HTML RAG maintain its essential status when developing applications which need context-aware and structured content generation.
Future Exploration
- Research efforts should concentrate on improving retrieval systems which will serve various domains including law and healthcare together with banking and finance. By optimizing the feedback mechanism with lower computational requirements HTML RAG will become more efficient and sought-after for users.
