
Mastering Reinforcement Learning: From Basics to Cutting-Edge Techniques

Topics in Reinforcement Learning (RL) explore how agents make their moves within environments to obtain the highest combined rewarding outcomes. The learning process of RL operates autonomously through environment interactions because it abstains from relying on labelled data to obtain rewards and punishments for feedback. Mastering the core principles of RL is essential for developing intelligent systems that can learn and adapt over time. Different components of RL technology have led to major breakthroughs throughout robotics, autonomous systems, finance, gaming, and healthcare applications.
The paper examines reinforcement learning from basic principles through advanced topics to deliver extensive information about its operational structure and its algorithms and applications as well as its present challenges.
1. Fundamentals of Reinforcement Learning
1.1 Key Components of RL
- Agent: The agent represents the user or decisional element that works directly with the environmental system.
- Environment: The environment serves as the area where agents perform their activities.
- State (S): The environment generates State (S) which expresses its current situation at a precise time.
- Action (A): The agent makes available moves through A which represents its possible conceivable actions.
- Reward (R): The feedback message Reward (R) notifies the system about action benefits.
- Policy (π): Agent selection strategies for determining actions are known as policies (π).
- Value Function (V): The Value Function helps evaluate how rewarding a state will be for future expected rewards.
- Q-Value (Q): Q-Value (Q) defines the predicted outcome when executing a specific action from its current state.
Mastering these foundational components is important to understanding how reinforcement learning works in real-world problem-solving.
1.2 Types of Reinforcement Learning
- Model-Free RL: Agents that perform Model-Free RL explore the environment through experimentation to gain knowledge rather than studying environmental dynamics.
- Model-Based RL: Through Model-Based RL agents construct environmental models which guide their future procedure.
1.3 The RL Process
The agent maintains an ongoing interaction with its environment which continues indefinitely.
- Observes the current state.
- An action is executed through a policy.
- The agent receives praise from environmental factors.
- Updates its knowledge and policy.
- The process continues for policy optimization and results in a learned optimal policy.
2. Mathematical Foundation: Markov Decision Processes (MDP)
MDPs give RL problems a standardized modeling framework that has four main components which include:
- A set of states (S)
- A set of actions (A)
- A transition function (T) defining state changes
- A reward function (R)
- Future rewards are evaluated through the discount factor (γ) within the framework of MDPs.
RL finds its core foundation in the Bellman Equation because it allows optimally calculating decision-making policies. It is given by:
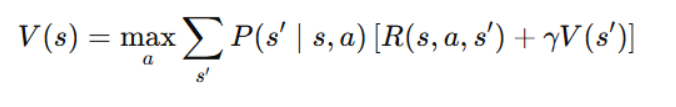
3. Core RL Algorithms
3.1 Value-Based Methods
- Dynamic Programming (DP): The algorithm Dynamic Programming (DP) solves optimal policies through Bellman equations.
- Monte Carlo (MC): The Monte Carlo (MC) method calculates value functions by analyzing episodes that have been sampled.
- Temporal Difference (TD) Learning: The method of Temporal Difference (TD) Learning combines the principles from Dynamic Programming and Monte Carlo techniques to perform learning from partial sequence information.
- Q-Learning: The iterative Q-value update mechanism makes Q-Learning one of the most widespread off-policy learning algorithms in recent times.
3.2 Policy-Based Methods
- Policy Gradient (PG): The Policy Gradient algorithm directly works on policy optimization without calculating value functions.
- Actor-Critic (AC): Combines value-based and policy-based methods for efficient learning.
4. Advanced Reinforcement Learning
4.1 Deep Reinforcement Learning
Deep RL integrates deep learning with RL to solve complex problems:
- Deep Q-Networks (DQN): Neural networks apply deep Q-Networks algorithms for Q-value approximation.
- Double DQN: In Double DQN the system decreases overestimation problems that occur when using Q-learning.
- Dueling DQN: The Dueling DQN method splits away value function evaluation from advantage function estimation.
- Deep Deterministic Policy Gradient (DDPG): Handles continuous action spaces.
- Proximal Policy Optimization (PPO): Balances exploration and exploitation efficiently.
Mastering advanced RL algorithms like DQN, PPO, and DDPG opens the door to solving high-dimensional, complex decision-making tasks that go beyond traditional settings.
4.2 Exploration vs. Exploitation
- ε-Greedy: The ε-Greedy Policy selects its best-known action most of the time yet performs random exploration with a probability level of ε.
- Upper Confidence Bound (UCB): The Upper Confidence Bound (UCB) explores and exploits through uncertainty-based decision making.
4.3 Multi-Agent Reinforcement Learning (MARL)
- Cooperative MARL: Agents under cooperative MARL work together to achieve maximum rewards for the entire group.
- Competitive MARL: The agents in competitive MARL systems operate in opposition to one another.
- Mixed MARL: Combines elements of both cooperation and competition.
5. Applications of Reinforcement Learning
- Robotics: Autonomous navigation, industrial automation.
- Finance: Algorithmic trading, portfolio management.
- Healthcare: Reinforcement Learning supports drug discovery and creates individualized healthcare treatment plans in the clinical sector.
- Gaming: AlphaGo, OpenAI Five, self-learning AI in video games.
- Autonomous Vehicles: Self-driving car decision-making.
6. Challenges in Reinforcement Learning
Despite its success, RL faces several challenges:
- Sample Inefficiency: Reinforcement learning demands a very large number of trial-and-error experiences to reach acceptable results.
- Stability Issues: Training systems experience instability because of significant variations that occur.
- Scalability: The extensive number of states along with actions in RL models creates difficulty for scaling operations.
- Interpretability: The interpretability factor makes it difficult for humans to understand which factors lead to decision outcomes.
7. Future of Reinforcement Learning
The development of artificial intelligence depends heavily on RL technology for its future applications..
Some key advancements include:
- Meta-learning: Meta-learning serves as a training mechanism to teach agents fast learning capabilities for new tasks.
- Hierarchical RL: Hierarchical reinforcement learning enables individuals to break complex problems into multiple smaller sub-problems for better efficiency.
- Multi-modal RL: Combining vision, language, and actions in a unified framework.
- Quantum RL: Quantum RL works to utilize quantum computers for making decisions at faster speeds.
Conclusion
The powerful learning technique “reinforcement learning” enables the solution of decisions which cannot receive direct supervision. Deep learning technology advances have led to significant achievement by reinforcement learning throughout multiple domains. Active research focuses on resolving issues regarding sample efficiency and stability and interpretability. The evolution of RL technology will open new possibilities for AI-sourced decision processes.
FAQs
1. What is reinforcement learning and how is it different from supervised learning?
Reinforcement learning (RL) is a learning paradigm where an agent interacts with an environment to learn optimal actions based on rewards or punishments. Unlike supervised learning, RL doesn’t use labeled data—instead, it learns through trial-and-error experiences.
2. What are the core components of a reinforcement learning system?
An RL system consists of:
- Agent (decision-maker)
- Environment (where the agent operates)
- State (S), Action (A), Reward (R)
- Policy (π): strategy to select actions
- Value Function (V) and Q-Value (Q) for evaluating outcomes
3. What is the role of the Bellman Equation in RL?
The Bellman Equation provides a recursive method to calculate the value of a state, forming the basis for many RL algorithms like Dynamic Programming and Q-learning. It helps determine the optimal policy by maximizing expected future rewards.
4. What are some real-world applications of reinforcement learning?
RL is applied in diverse domains, including:
- Robotics – for autonomous navigation and manipulation
- Finance – in trading algorithms and portfolio management
- Healthcare – personalized treatment plans and drug discovery
- Gaming – like AlphaGo and OpenAI Five
- Autonomous vehicles – for decision-making and path planning
5. What are the major challenges in reinforcement learning today?
Current challenges include:
- Sample inefficiency – needing vast interactions to learn
- Training instability – due to fluctuating learning dynamics
- Scalability – difficulty managing large state/action spaces
- Interpretability – hard to explain why certain decisions are made
