
Replug RAG: The Ultimate Guide to Retrieval-Augmented Generation
Replug RAG is a refined variant of RAG technique designed to improve flexibility, accuracy, and performance by separating the retriever and generator stages into modular and reusable components.

This article delves into the Replug RAG technique, explaining how it works, when and where it can be applied, its advantages and disadvantages, and its step-by-step implementation, supplemented with Python code and diagrams.
1. How Does Replug RAG Work?
Replug RAG operates in two distinct stages:
a. Retrieval Stage:
- A retriever model fetches relevant documents, passages, or information from a knowledge base based on the input query.
- Unlike traditional RAG models where retrievers are tightly integrated, Replug allows the retriever to be independently updated or replaced without modifying the generator.
b. Generation Stage:
- A generative model, such as GPT or BART, generates an answer or response by combining the retrieved information with the input query.
- The generator processes the context retrieved in the first stage to produce accurate and context-aware responses.
Key Differentiator: The retriever and generator in Replug RAG are designed to work modularly, meaning the retriever can use advanced retrieval techniques (e.g., dense retrieval, BM25) without disrupting the generation process.
2. When and Why to Use Replug RAG?
When to Use Replug RAG
- Complex Queries:
- Replug RAG is ideal when user queries are intricate and require combining external knowledge from updated sources with existing datasets.
- Example: Answering detailed questions about a product by retrieving the latest product information from a database or online source and blending it with internal sales data.
- Dynamic Knowledge Sources:
- It excels in scenarios where knowledge bases are frequently updated or dynamic, and the system needs real-time retrieval capabilities.
- Example: Industries like finance, e-commerce, or healthcare, where regulations, pricing, or inventory change regularly, can benefit from the dynamic nature of RAG.
- Low Training Resources:
- When fine-tuning a large generative AI model becomes resource-intensive in terms of time, computational power, and cost, RAG serves as a cost-effective alternative.
- Instead of re-training the model, RAG retrieves relevant information from external sources in real-time, ensuring efficiency and relevance without needing extensive fine-tuning.
Why Use Replug RAG?
- Enhanced Accuracy:
- By combining the power of retrieval and generation, Replug RAG delivers more accurate and contextually relevant responses compared to a standalone generative model.
- Real-Time Updates:
- The ability to retrieve and incorporate the latest information ensures that responses are always current and reliable, making it invaluable in dynamic environments.
- Resource Efficiency:
- Reduces the need for heavy computational resources typically required for model training or retraining, enabling smaller teams or organizations to leverage cutting-edge AI capabilities.
- Scalability Across Use Cases:
- RAG can adapt to a variety of industries and use cases, such as customer support, research, content generation, or technical troubleshooting, making it highly versatile.
- Customizable Knowledge Integration:
- RAG allows organizations to integrate proprietary data, ensuring that responses are not only accurate but also tailored to specific business needs.
Pros and Cons of Replug RAG
Pros
- Modularity:
- One of the key advantages of Replug RAG is its modularity, which allows independent upgrades for the retriever and the generator components.
- Benefit: The advantage of this modular design is that each component can develop independently in response to technological progress or changing needs. For instance, should a superior retrieval algorithm be introduced, it is possible to enhance the retriever without necessitating a complete redesign of the entire model.
- Customizability:
- Replug RAG supports tailored retrievers that are specific to different domains or use cases, ensuring that the knowledge retrieval process is aligned with the particular needs of the business or application.
- Benefit: This customizability improves relevance because the retriever can be fine-tuned to prioritize certain types of data or sources, ensuring that retrieved information is more aligned with the query’s context. For instance, in the healthcare industry, a retriever could be specifically designed to prioritize medical literature or clinical studies, thus improving the quality and specificity of the generated content.
- Efficiency:
- Replug RAG increases efficiency by reusing retrieval components across different use cases and queries, thereby reducing redundancy.
- Benefit: This makes the system more resource-efficient because the same retrieval logic can be applied to multiple scenarios, minimizing the computational overhead involved in processing each new query. It also reduces the need for retraining a generative model from scratch for each different application.
- Data Freshness:
- Replug RAG enables real-time retrieval from frequently updated knowledge sources, ensuring that the model always has access to the most current data.
- Benefit: This is particularly useful in industries where data is constantly changing, such as finance, news, and e-commerce. The system can pull in the latest information, providing up-to-date responses rather than relying on outdated pre-trained data, which is often a limitation in traditional generative models.
- Transparency:
- Replug RAG’s architecture offers greater transparency, as the retrieval and generation components are separate and easy to debug independently.
- Benefit: This separation facilitates identifying and resolving problems as they occur. For instance, if the produced response lacks relevance or accuracy, the source of the issue can be pinpointed to either the retrieval phase (where the information was obtained) or the generation phase (how the information was applied), thereby enabling more efficient troubleshooting.
Cons
- Integration Complexity:
- The system’s reliance on multiple components (retriever, generator, and sometimes a post-processing layer) introduces a level of integration complexity.
- Challenge: The need to carefully orchestrate these components can lead to challenges in maintaining system stability and ensuring smooth communication between the retriever and generator. Proper integration is crucial to avoid issues like mismatched data between the retrieval and generation steps, which can lead to incorrect or nonsensical outputs.
- Latency:
- Retrieval introduces additional processing time, adding latency to the overall response time of the system.
- Challenge: While the retrieval step enhances the quality and relevance of responses, it can slow down the process. In time-sensitive applications such as customer support or real-time recommendation systems, this latency might negatively affect the user experience, making it important to balance retrieval quality with processing speed.
- Dependency on Retriever Quality:
- The effectiveness of Replug RAG is significantly influenced by the quality of the retriever. Inadequate retrieval can compromise the performance of the entire system, regardless of the generative model’s advanced capabilities.
- Challenge: When the retriever retrieves irrelevant or erroneous information, the generator is likely to generate responses that are inaccurate or unhelpful. This underscores the necessity of ongoing refinement of the retriever to ensure it can comprehend and address queries effectively.
- Scalability Challenges:
- As the size of the knowledge base grows, scaling the retriever becomes increasingly challenging, requiring significant storage and computational resources.
- Challenge: Large-scale systems may need powerful infrastructure to handle vast amounts of data, and ensuring that retrieval remains fast and accurate across such large datasets may require advanced optimization techniques. In some cases, scaling the retrieval system might also introduce additional operational costs or system complexity, which businesses must carefully manage.
4. Where to Use Replug RAG?
Replug RAG is applicable in several domains:
- Customer Support: Generating context-aware responses using dynamic knowledge bases.
- Education: Providing precise answers to queries from large repositories of textbooks.
- Healthcare: Assisting doctors by retrieving and summarizing clinical data.
- E-commerce: Improving product recommendations and answering customer queries.
- Research: Summarizing and synthesizing information from scholarly articles.
5. Implementation of Replug RAG
Below is a step-by-step explanation and Python implementation of Replug RAG using a dense retriever and a GPT-based generator.
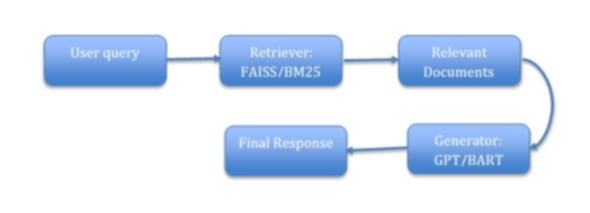
Step 1: Define the Knowledge Base
The knowledge base can be a collection of documents, FAQs, or other structured data sources.
Step 2: Set Up the Retriever
Use a dense retriever like FAISS (Facebook AI Similarity Search) or a BM25 algorithm to index and retrieve relevant documents.
Step 3: Connect the Retriever and Generator
Pass the retrieved documents to the generator as context.
Step 4: Generate the Final Response
Use a generative model (e.g., GPT) to create a response based on the retrieved context.
6. Python Implementation with Diagrams
The following implementation demonstrates Replug RAG using Python.
a. Setup
# Install necessary libraries !pip install transformers faiss-cpu from transformers import AutoTokenizer, AutoModelForSeq2SeqLM import faiss import numpy as np
b. Create a Knowledge Base
# Sample knowledge base
documents = [
"The Earth revolves around the Sun.",
" Water reaches boiling point at hundred degrees Celsius when at sea level.",
"Python is a versatile programming language.",
"The capital of France is Paris.",
"Machine learning involves training algorithms on data."
]
# Encode documents using embeddings (for demonstration, random embeddings are used)
def create_embeddings(docs):
return np.random.rand(len(docs), 128)
embeddings = create_embeddings(documents)
c. Set Up the FAISS Retriever
# Create FAISS index
index = faiss.IndexFlatL2(128)
index.add(embeddings)
def retrieve(query, k=2):
query_embedding = np.random.rand(1, 128) # Replace with actual query embedding
distances, indices = index.search(query_embedding, k)
return [documents[i] for i in indices[0]]
# Example query
query = "What is the capital of France?"
retrieved_docs = retrieve(query)
print("Retrieved Documents:", retrieved_docs)
d. Connect to a Generative Model
# Load pre-trained generative model
tokenizer = Auto Tokenizer .from_pretrained("facebook/bart-large-cnn")
generator = Auto Model ForSeq2SeqLM.from_pretrained("facebook/bart-large-cnn")
# Generate response
def generate_response(query, context):
input_text = query + "\n" + "\n".join( context)
inputs = tokenizer. encode( input_text, return_tensors="pt", max_length=512, truncation=True)
outputs = generator. generate( inputs, max_length=50, num_beams=5, early_stopping=True)
return tokenizer. decode(outputs[0], skip_special_tokens=True)
response = generate_response(query, retrieved_docs)
print("Generated Response:", response)
Conclusion
Replug RAG represents a robust and adaptable approach for integrating retrieval and generation within natural language processing tasks. By separating the retriever and generator elements, it facilitates independent optimization and enhances scalability. Despite certain challenges, the advantages of modularity, precision, and efficiency render it an essential resource for a range of practical applications. Further Exploration: Consider experimenting with various retrievers (such as BM25 and dense retrievers) and generators (including T5 and GPT) to optimize the pipeline for your particular requirements.
