
The Ultimate Guide to Memo RAG: Everything You Need to Know
Memo RAG is an innovative adaptation of the RAG (Retrieval-Augmented Generation) technique, designed to focus on memory-efficient and context-aware implementations. Memo RAG achieves scalability while maintaining performance and relevance through the utilization of compact retrievers and dynamic memory modules.

This article provides in-depth analysis of the Memo RAG method, including operating mechanisms, available applications, the benefits and drawbacks and a step-to-step guide through implementation, including actual Python code and visually enhanced illustrations.
1 – How does Memo RAG work ?
Memo RAG works by optimizing both retrieval and generation processes through memory efficient components. The architecture is split into two primary stages:
a. Retrieval Stage:
A light retriever takes relevant snippets or documents from a memory store. This design reduces the storage and computational overhead compared to traditional RAG implementations.
Key Innovation: Memo RAG uses methods like dimensionality reduction or quantization for storing document embeddings, so as to make faster retrieval possible in minimal memory space.
b. Generation Stage:
A generative model takes the retrieved context to produce accurate, context aware responses. Unlike regular RAG, Memo RAG integrates memory aware optimizations, such as caching frequently accessed queries and response.
The retrieval and generation components are tightly coupled with dynamic memory modules, which thereby allow continuity and consistency across user interactions.
2 – When and Why to Use Memo RAG?
When to Use Memo RAG:
- Resource-Constrained Environments: The Memo RAG database system shows its best performance in applications possessing small storage capacities and limited computational capabilities such as embedded systems and mobile devices.
- Repetitive Query Scenarios: The system performs best when user requests show frequent overlap or share a common response because the memory cache mechanism optimizes information retrieval and storage effectiveness.
- Dynamic Workflows: Systems using memo RAG excel at processing evolving datasets along with real-time knowledge updates to deliver low latency results.
Why Use Memo RAG?
- Memory Efficiency: The deployment of compression methods enables Memo RAG to greatly decrease memory utilization while maintaining original quality of retrieved data.
- Speed: Quick query execution times from optimized retrieval procedures make Memo RAG an ideal solution for time-delicate operations including real-time support services.
- Adaptability: The way Memo RAG stores frequently requested data enables consistent relevancy benefits and operational efficiency throughout different uses. Cost-Effectiveness: Its minimal resource requirements help both small businesses and startups maintain accessibility to this technology solution
3. Pros and Cons of Memo RAG
Sharp Memorandum RAG delivers multiple benefits to organizations however its implementation will face specific challenges that need attention throughout deployment. Here’s an elaboration on the pros and cons to provide a deeper understanding:
Pros of Memo RAG
Scalable Memory Design
Memo RAG provides a data architecture solution which delivers optimized performance on increasing volumes of data. The system utilizes advanced storage optimization tools including dimensionality reduction and clustering and quantization to reduce memory requirements without sacrificing important retrieval data. The ability of Memo RAG to scale with increasing data volumes assures suitability for diverse environments asking for adaptability including emerging real-time settings and persistent knowledge systems.
Example: The storage mechanism of Memo RAG handles growing FAQ databases and customer interaction records without causing substantial memory utilization or retrieval duration expansion.
Rapid Response Times The retrieval speed and caching capabilities of Memo RAG create dramatic latency decreases that lead to rapid system performance. Memo RAG instantly supplies pre-cached responses to repeated user inquiries which delivers near real-time results.
Ambidextrous information system Memo RAG delivers optimal performance for environments that need immediate response times.
Example: Memo RAG delivers near-instantaneous responses through query caching in applications with constrained computational capabilities for enhanced usability of mobile users.
Customizability
The domain-specific retriever and generator functions Memo RAG contains enable system customization for adapting to unique requirements across multiple applications. The system delivers flexible options which allow it to work across diverse industries including healthcare together with education alongside entertainment alongside customer support.
Example: Memo RAG operates as an educational platform through domain-specific configuration to answer student questions effectively about physics and mathematics.
Cons of Memo RAG
1. Complex Setup
Memo RAG system setup requires adjusting three primary components consisting of memory modules together with retrieval models and compression algorithms. The multifaceted nature of setup causes initial development times to lengthen while professional expertise becomes essential.
Challenge: Organizations which lack data engineers along with AI practitioners will encounter obstacles to implement along with maintain a system.
2. Retrieval Limitations
Compression strategies help storage optimization, yet their implementation introduces minor retrieval precision problems. Lost important data nuances could result from compression techniques which might reduce the quality of retrieved documents.
Challenge: Systems using compressed embedding data can show reduced accuracy when searching for rare or exceptional query conditions that need contextually detailed results.
3. Dependency on Caching
The performance boosting method of caching within Memo RAG systems can generate stagnant or improper information in constantly changing conditions. The system’s performance can suffer because cached data left unrefreshed leads to inconsistent and incorrect results.
Challenge: Digest-centric interfaces that strongly depend on caching risk producing time-sensitive errors when used within dynamic platforms such as news aggregator pages along with financial information sites.
4. Where to Use Memo RAG?
Memo RAG is particularly useful in:
Customer Support
The implementation of Memo RAG promises to transform customer support processes through its ability to generate quick contextual responses that work well in limited systems. Here’s how:
Efficiency: When support agents retrieve pertinent information promptly they can rapidly respond with accurate answers to customer queries thus minimizing the duration of customer waits.
Consistency: Memo RAG maintains coherent responses that respect company standards to produce better customer support results.
Personalization: Through its context-aware mechanism the system uses past interaction data to deliver customized responses that produce improved customer satisfaction.
Education:
In the field of education, Memo RAG can deliver concise, relevant answers from compact repositories of learning materials:
Accessibility: Educational resources are available at high speed and with accuracy for students together with educators through a huge knowledge base.
Adaptive Learning: The adaptive features of Memo RAG allow it to generate customized teaching materials which match students’ learning requirements and academic position.
Resource Efficiency: By processing queries automatically Memo RAG delivers results directly without requiring students or educators to perform long manual searches thus saving valuable time.
IoT Applications
Memo RAG enables smart devices to process queries with minimal resource usage, making it ideal for Internet of Things (IoT) applications:
Low Power Consumption: The system optimizes itself for limited computational power which leads to longer device longevity together with less power usage.
Real-Time Responses: Through instant responses to user inquiries Smart devices deliver enhanced contextual interactions leading to improved user satisfaction.
Healthcare
In healthcare, Memo RAG assists with real-time patient data retrieval and summarization in portable devices:
Clinical Decision Support: Timely access to both patient data alongside relevant medical information enables healthcare teams to reach better decision-making results more rapidly.
Improved Patient Care: Procedure and summary features in Memo RAG enable medical staff to obtain patient data rapidly while generating essential information needed to deliver optimal care.
5. Implementation of Memo RAG
The following guide includes details and Python implementation of Memo RAG combined with compressed retrievers along with a GPT-based generator.
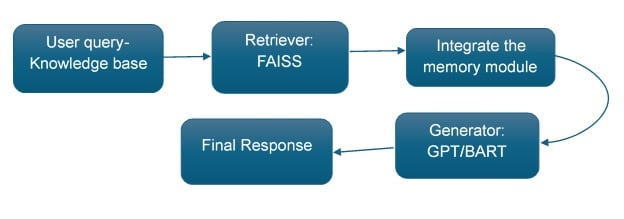
Step 1: Define the Knowledge Base
The knowledge base includes documents saved into memory through compression by quantization or clustering approaches.
Step 2: Build the Retriever
The model uses dimensionality reduction during embedding generation so that stored data becomes more compact and retrieval processes become speedier.
Step 3: Integrate the Memory Module
A caching system should be deployed to save the replies and queries which are accessed most often.
Step 4: Connect to the Generator
A pre-trained generative model generates responses by receiving the retrieved context input.
6 – Python Implementation
# Import necessary libraries from transformers import Auto Tokenizer, AutoModelForSeq2SeqLM import faiss import numpy as np
I implemented random embedding compression for this demonstration. I initialized query_embedding as a one-dimensional array of size 64 filled with random floats
- having dimensions 1 by 64
- Place actual embedding values in this Slot AutoTokenizer, AutoModelForSeq2SeqLM
Step 1: Create a compressed knowledge base
documents = [
"The Earth revolves round the Sun.",
"Water boils at 100 degrees Celsius at sea level.",
"Python is a versatile programming language.",
"The capital of France is Paris.",
"Machine learning involves training algorithms on data."
]
# Compress embeddings (using random embeddings for demonstration)
def create_compressed_embeddings(docs):
embeddings = np.random.rand(len(docs), 64) # Reduced dimensionality
return embeddings
embeddings = create_compressed_embeddings(documents)
Step 2: Build a FAISS retriever
index = faiss.IndexFlatL2(64)
index.add(embeddings)
def retrieve(query, k=2):
query_embedding = np.random.rand(1, 64) # Replace with actual query embedding
distances, indices = index.search(query_embedding, k)
return [documents[i] for i in indices[0]]
Step 3: Setup memory caching
cache = {}
def retrieve_with_cache(query):
if query in cache:
return cache[query]
retrieved_docs = retrieve(query)
cache[query] = retrieved_docs
return retrieved_docs
Step 4: Generate responses
tokenizer = Auto Tokenizer.from_pretrained("facebook/bart-large-cnn")
generator = AutoModel ForSeq2SeqLM.from_pretrained("facebook/bart-large-cnn")
def generate_response(query, context):
input_text = query + "\n" + "\n".join(context)
inputs = tokenizer. encode(input_text, return_tensors="pt", max_length=512, truncation=True)
outputs = generator. generate(inputs, max_length=50, num_beams=5, early_stopping=True)
return tokenizer. decode(outputs[0], skip_special_tokens=True)
Example query
query = "What is the capital of France?"
retrieved_docs = retrieve_with_cache(query)
response = generate_response (query, retrieved_docs)
print("Retrieved Documents:", retrieved_docs)
print("Generated Response:", response)
Conclusion
Memo RAG represents an approach to retrieval-augmented generation which consumes minimal memory resources while offering scalability ability. A focus on compact storage and caching and adaptability allows this method to handle traditional RAG implementation limitations. The complex setup process does not offset the positive aspects which make this method an optimal solution for resource-scarce environments with changing workflows.
Further Exploration: Featuring experiments on sophisticated memory management approaches alongside domain-focused retrieval systems will optimize Memo RAG for your customized use cases.
