
Credit Card Fraud Detection using Machine Learning
As we’re moving towards the digital world — cybersecurity is getting a critical part of our life. When we talk about security in digital life also the main challenge is to find the abnormal activity.

When we make any transaction while buying any product online — a good amount of people prefer credit cards. The credit limit in credit cards occasionally helps us me making purchases even if we don’t have the amount at that time. but, on the other hand, these features are misused by cyber attackers.
To, attack this problem we need a system that can cancel the transaction if it finds problematic.
Then, comes the need for a system that can track the pattern of all the transactions and if any pattern is abnormal also the transaction should be cancelled.
Today, we’ve numerous machine learning algorithms that can help us classify abnormal transactions. The only necessity is the old data and the suitable algorithm that can fit our data in a better form.
In this article, I’ll help you in the complete end- to- end model training process — finally you’ll get the best model that can classify the transaction into normal and abnormal types.
The data for this article can be found here. This dataset contains the real bank transactions made by European cardholders in the year 2013. As a security concern, the actual variables are not being shared but — they have been transformed versions of PCA. As a result, we can find 29 feature columns and 1 final class column.
We will start by importing all the necessary libraries in one place — so that we can modify them quickly.
Now, we will read out dataset with pandas module read_csv().
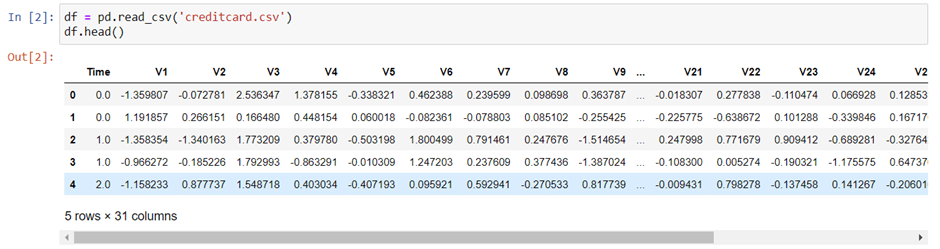
To check the shape of our data and value counts we can use shape function and value_counts() function.
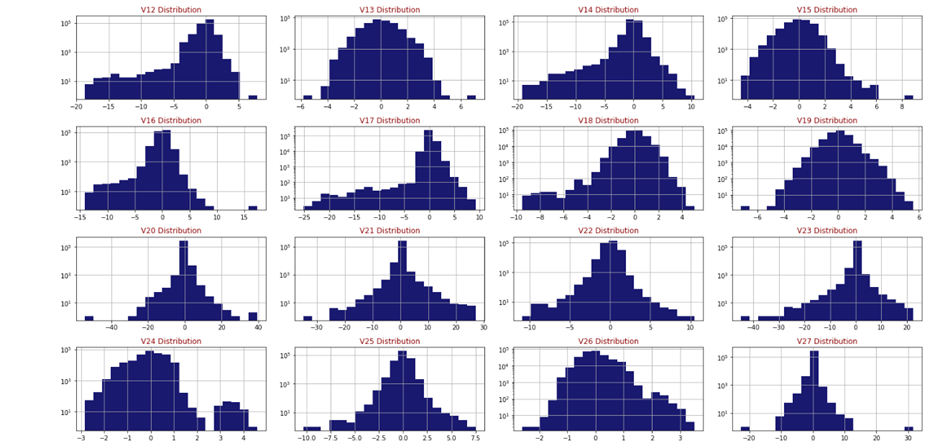
We will check how our data is distributed with the help of histogram.

Before splitting train & test — we need to define dependent and independent variables. The dependent variable is also known as X and the independent variable is known as y.

Model Building
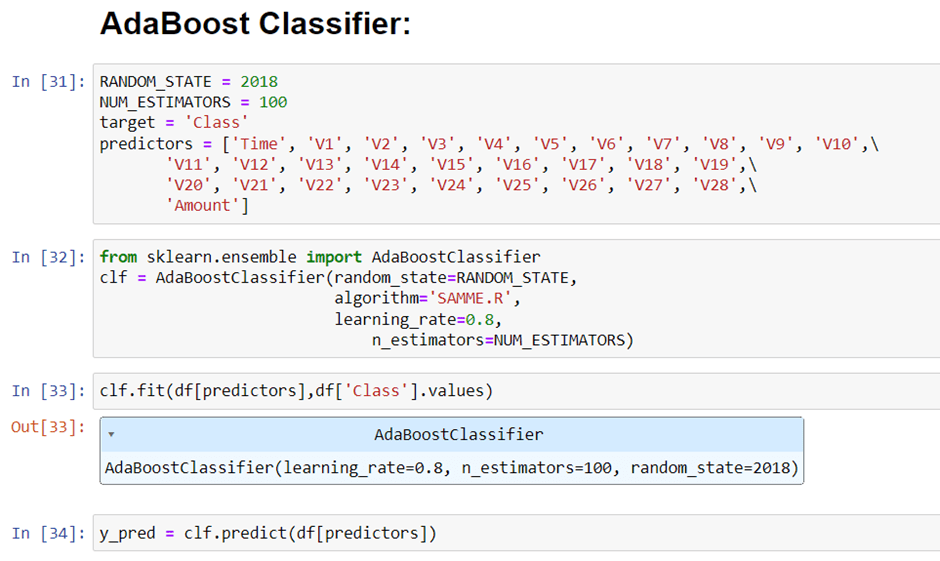
We will be trying different machine learning models one by one. Defining models are much easier. A single line of code can define our model. And, in the same way, a single line of code can fit the model on our data.

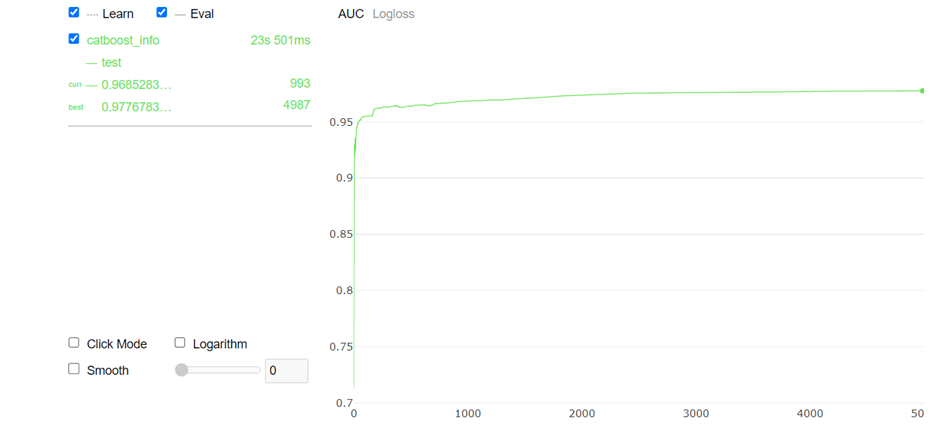
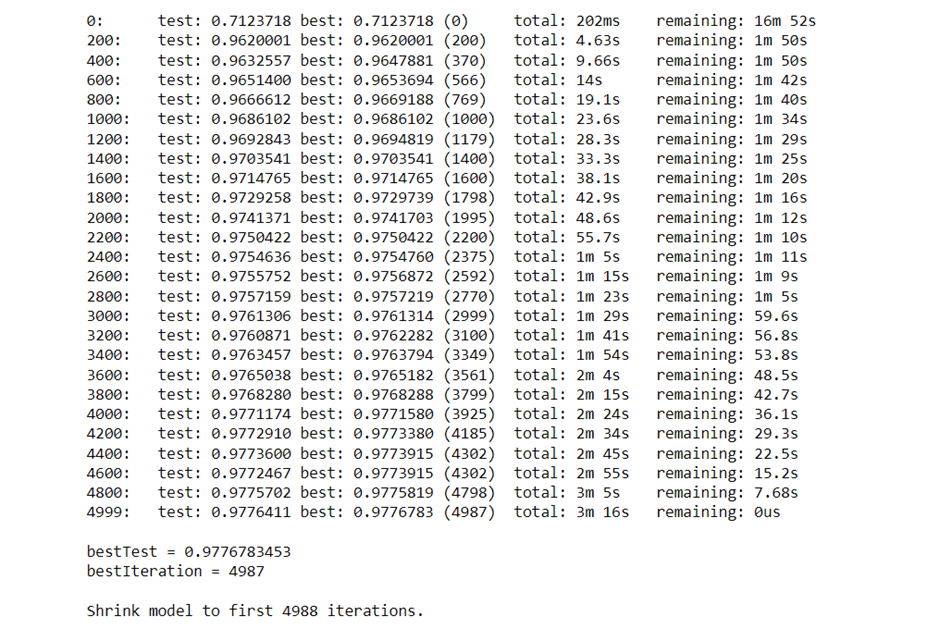
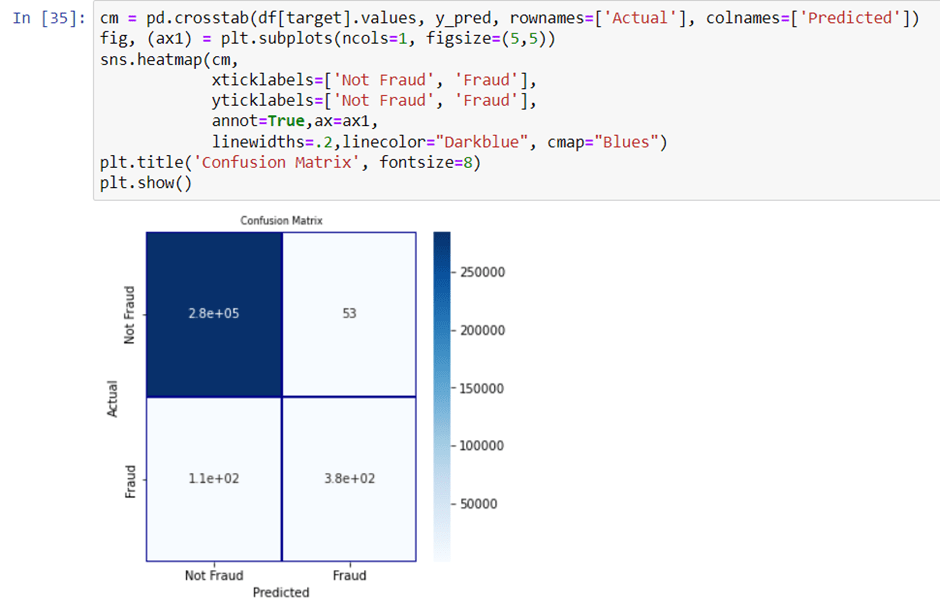
Checking the confusion matrix:

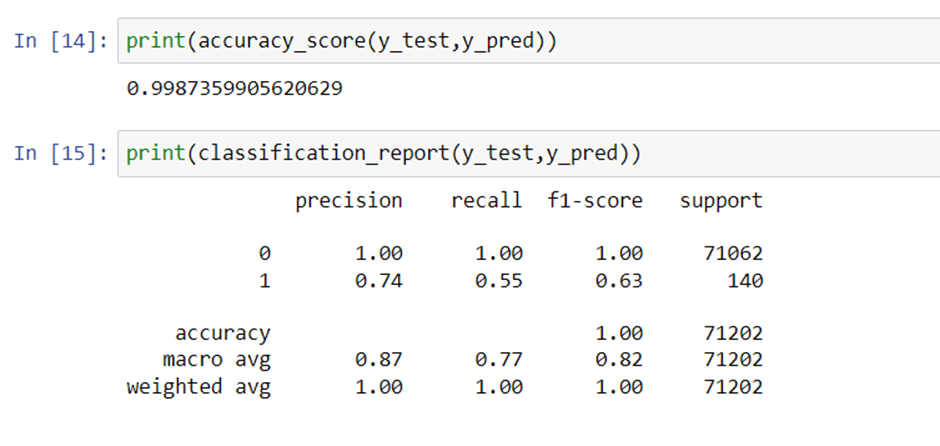
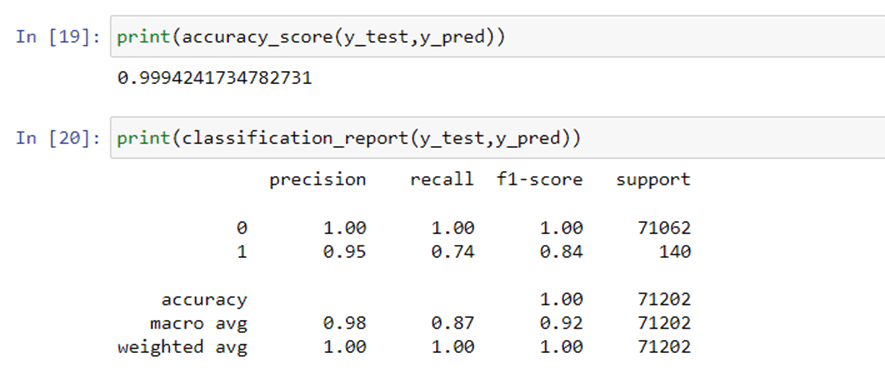
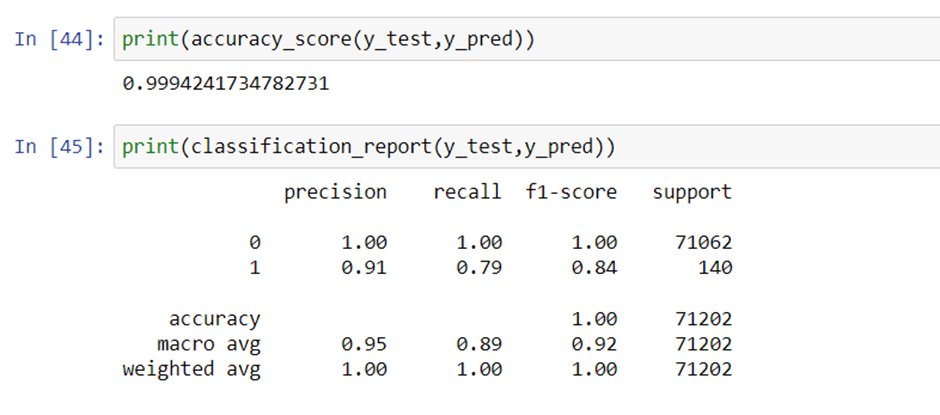
Checking the accuracy and classification report:
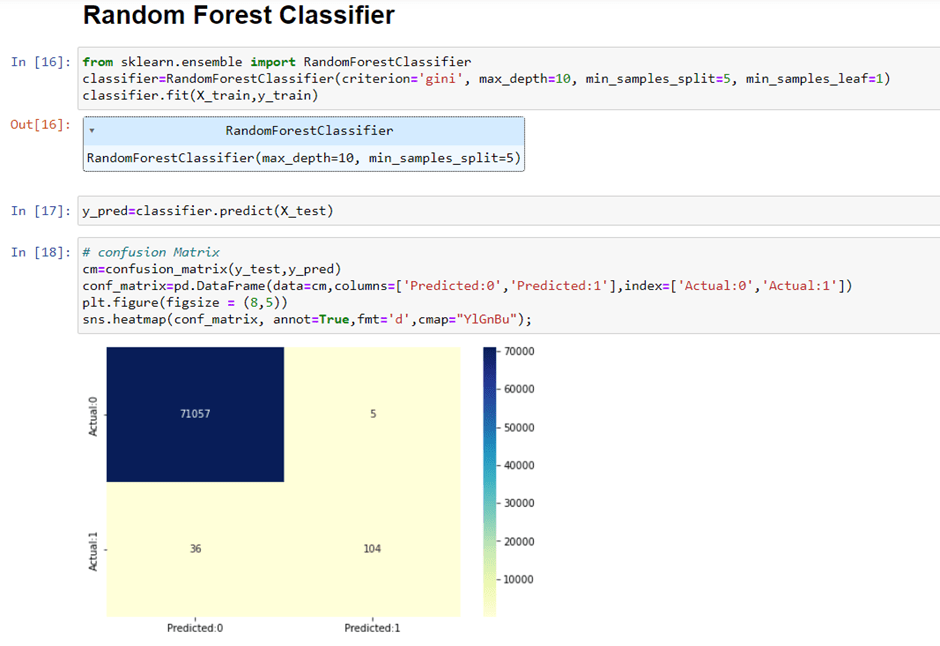
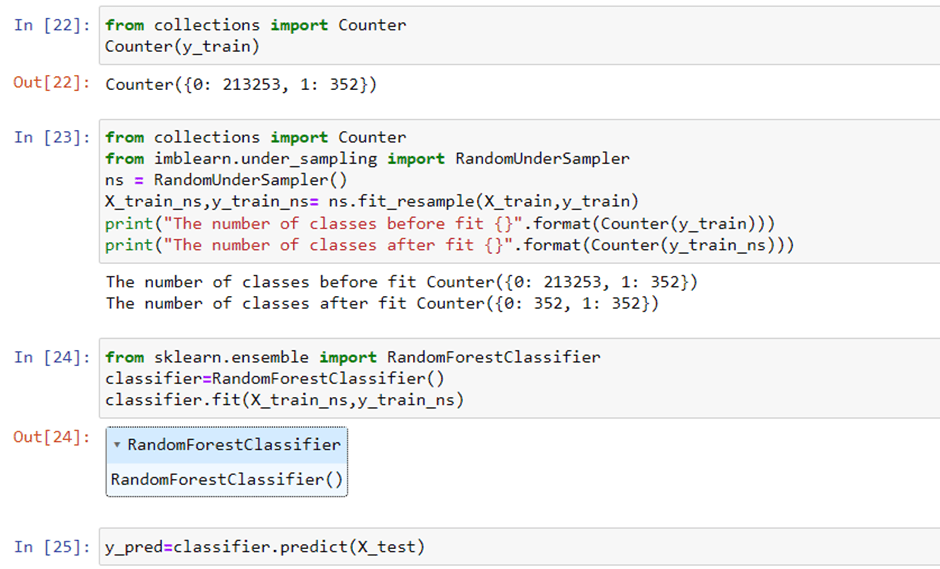
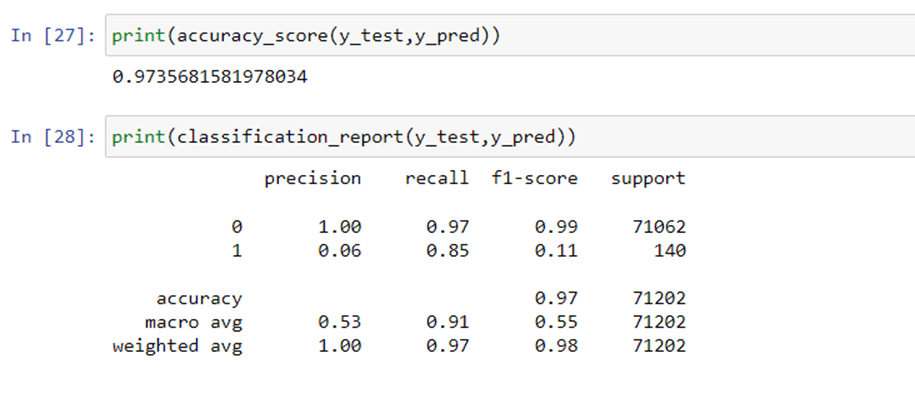
Checking the accuracy and classification report for Random Forest Classifier:
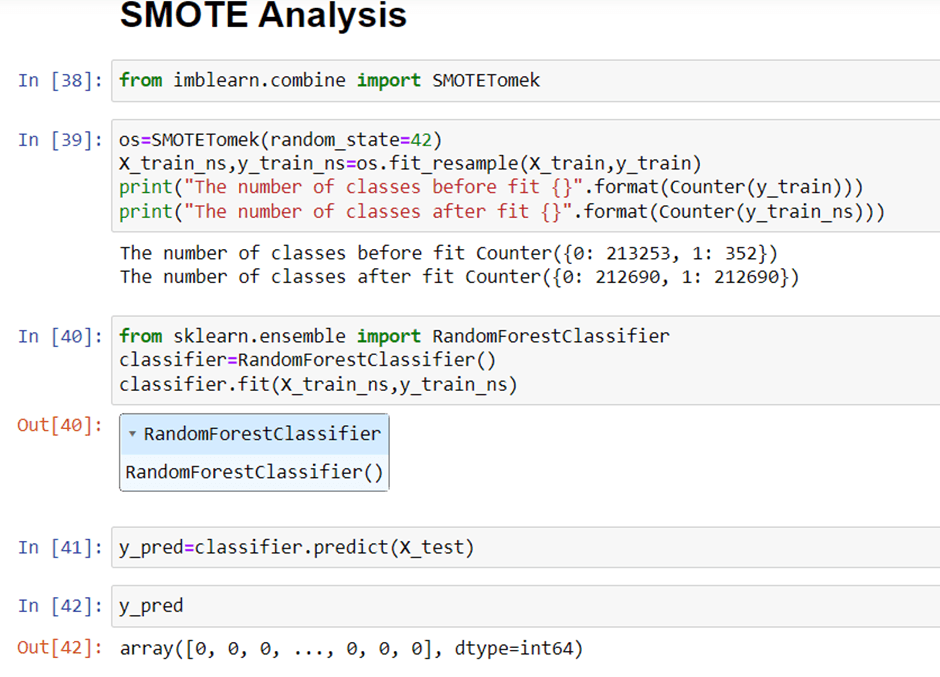
Random Resampling Imbalanced Datasets
There are two main approaches to random resampling for imbalanced classification; they are oversampling and under sampling.
- Random Oversampling: Randomly duplicate examples in the minority class.
- Random Under sampling: Randomly delete examples in the majority class.
Random oversampling involves randomly selecting examples from the minority class, with replacement, and adding them to the training dataset. Random undersampling involves randomly selecting examples from the majority class and deleting them from the training dataset.


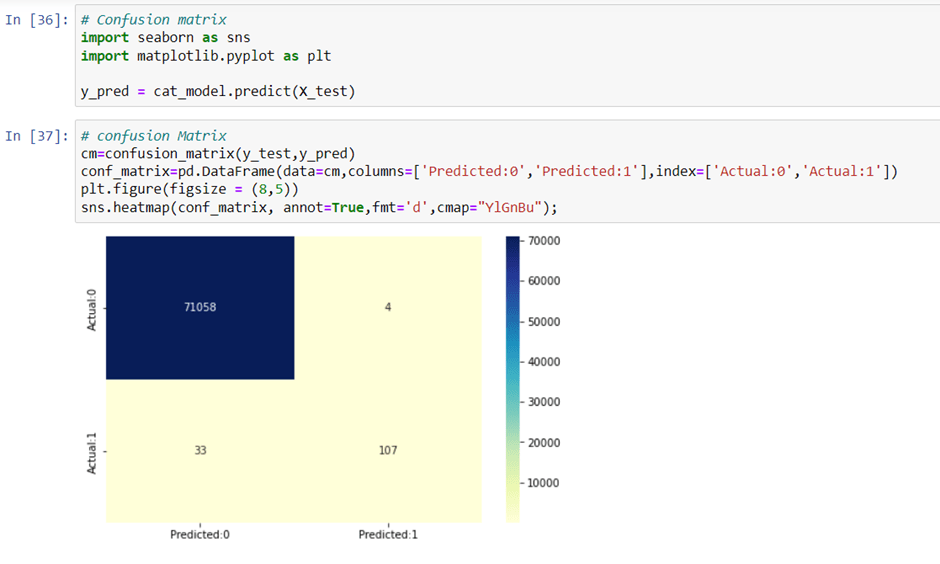
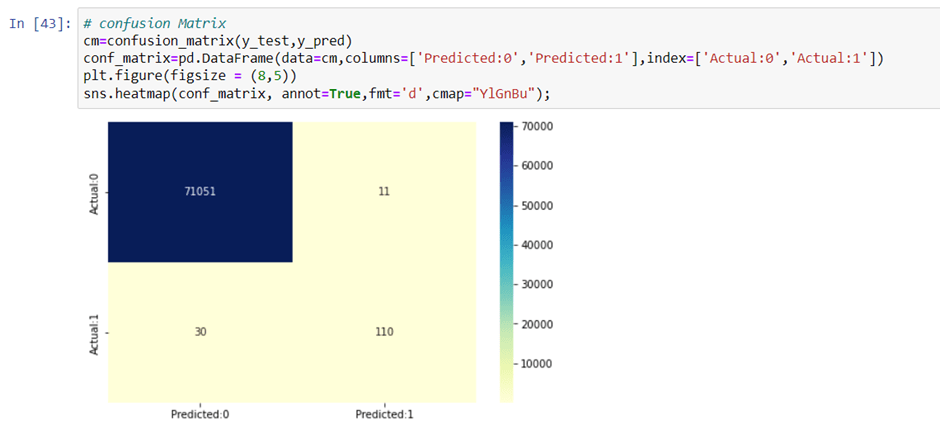
Conclusion
Well, great We just received 99.94% accuracy in our credit card fraud detection. This number should not be surprising as our data was balanced towards one class.
