
What is bias and variance in Machine Learning?
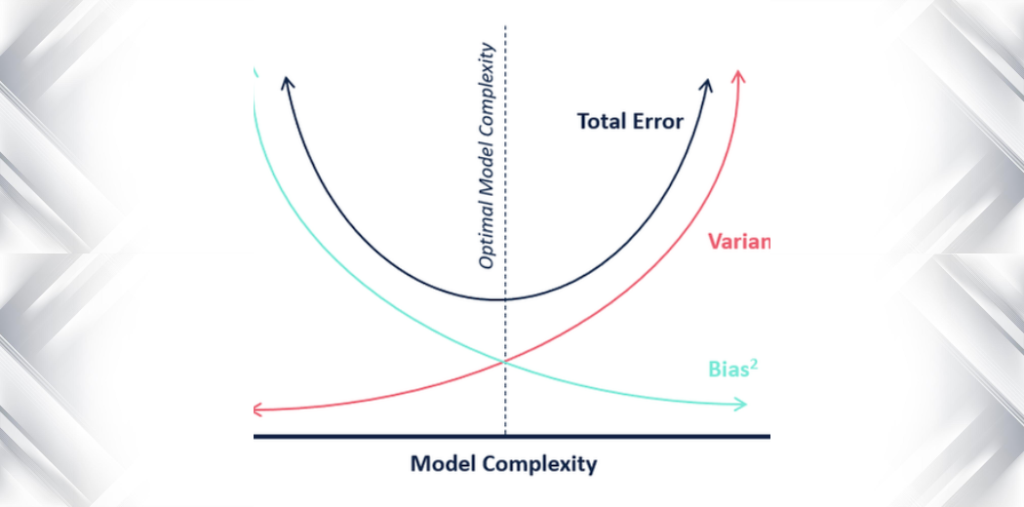
When we talk about modeling, it’s important to understand the way models deal with errors (bias and variance). There are tradeoffs between how well a model can reduce these errors. Understanding the errors in your models can help you to avoid the mistake of overfitting and underfitting.
What is bias?
Bias is the average that our model predicts vs what it’s supposed to be predicting. With high bias, a model cannot be trusted, giving you skewed data and high error.
What is variance?
Variance is the variation in the predictions that a given model makes. Models with large variance pay a lot of attention to the training data and don’t generalize well on unseen data, whereas models with smaller variance may not give as much weight to your training data but still produce accurate predictions for novel examples. As a result, such models are able to learn without trouble on data they’ve seen before and then have hard time making predictions with new data.
Bias and variance using bulls-eye diagram
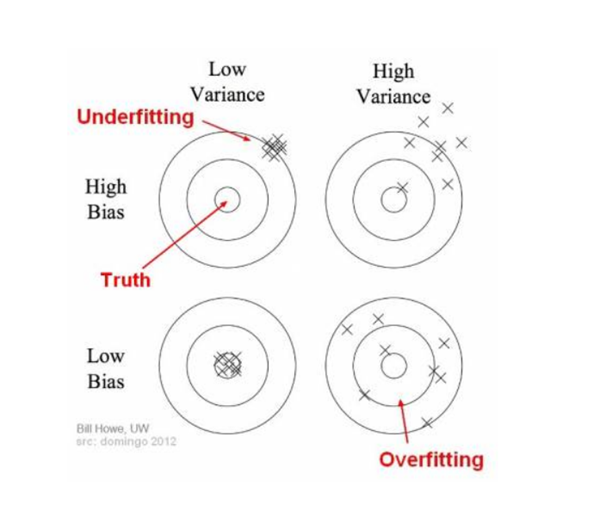
The center is an area of perfect hits, while the areas on the outer edge have a lower accuracy. We can find separate areas of high accuracy by applying our model again, which extrapolates more values to create more accurate predictions.
The cases where a model fails to identify the underlying pattern of data in supervised learning are called underfitting. Models such as these have a high bias and low variance. When you don’t have enough input data and need to find patterns in nonlinear relationships, these models will likely fail because they can’t capture complex patterns. These types of models are also easy to create but not intuitive for users without subject knowledge.
In supervised learning, overfitting is when our model captures the noise along with the underlying pattern in data. It can happen when we train our model a lot on noisy datasets. These models have low bias and high variance. These models are very complex like Decision trees which are prone to overfitting.
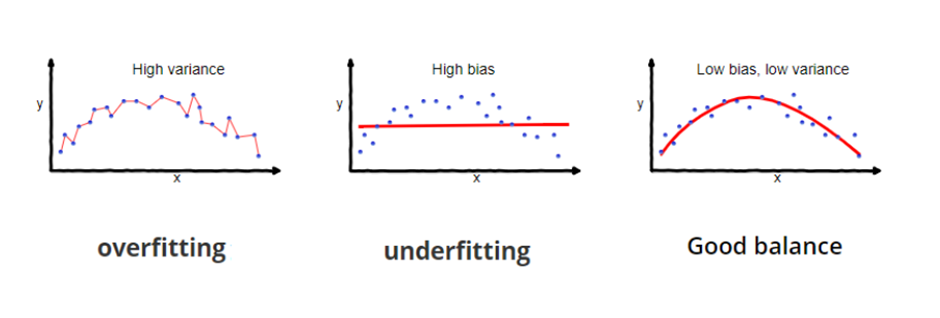
Why is Bias Variance Tradeoff?
If our model is too simple and has very few parameters, it may have high bias and low variance. Conversely, if our model has many parameters then it’ll have high variance but low bias. Finding the optimal balance between overfitting and underfitting should be a goal This tradeoff in complexity is why there is a tradeoff between bias and variance. An algorithm can’t be less complex while also being more complex.

I got good info from your blog