
Overfitting in Machine Learning: What it is and When it Occurs
In machine learning, overfitting refers to the phenomenon where a model performs well with training data, but does not generalize well to new, unseen data. Overfitting occurs when the model is too complex for the amount of training data.
To understand overfitting, let’s look at an analogy. Imagine you are in a foreign country and someone steals something from you. If you were to generalize and say that everyone in this country is a thief, that would be an example of an exaggeration. Just like with machine learning, you made your conclusion based on a small sample and your conclusion cannot be generalized to the entire population.
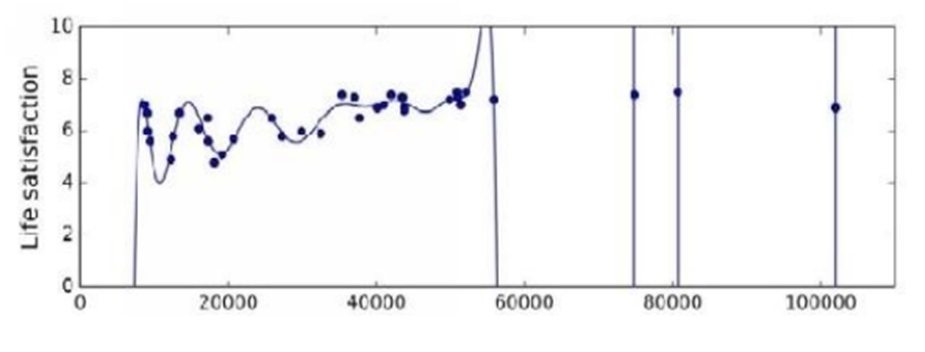
Overfitting in machine learning is a common problem that occurs when a model is too complex and has too many parameters relative to the size of the training data. In such cases, the model fits the training data too closely, including noise or random variations in the data. As a result, the model loses generalizability and makes poor predictions based on new data.
Solution for overfitting
There are several solutions to avoid overfitting. One way is to gather more data for the training set. With more data, the model can learn to describe the problem more generally, reducing the risk of overfitting.
Another solution is to denoise the training data by removing unnecessary or irrelevant features. This simplifies the model and makes it less responsive.
Finally, choosing a model with fewer parameters can also help reduce overfitting. A simpler model with fewer parameters is unlikely to fit the training data too closely and may generalize better to new data.
Conclusion
overfitting is a common problem in machine learning that occurs when the model is too complex for a given amount of training data. To avoid overfitting, data collection, noise reduction, and model selection with smaller parameters can help improve the model’s ability to generalize and predict new data.
