
Reinforcement Learning: Maximizing Rewards through Continuous Learning and Markov Decision Processes

Reinforcement learning (RL) is a subfield of machine learning that focuses on using reward functions to train agents to make decisions and actions in an environment that maximizes their cumulative reward over time. RL is one of the three main machine learning paradigms, along with supervised and unsupervised learning.
There are two main types of reinforcement learning: continuous reinforcement learning and Markov decision processes. During continuous reinforcement learning, the agent is given a goal and a gain function that maps each state-action pair to a scalar reward that it can receive from the environment. The goal of an agent is to maximize rewards by performing actions that are useful for a given task, i.e., to maximize the utility function.
In Markov decision processes, the agent’s policy changes as it observes the environment and learns from its experiences. This means that the algorithm constantly updates its strategy based on the feedback it receives, allowing it to adapt to new scenarios and improve its decision making over time.
The ultimate goal of reinforcement learning is to enable machines to learn and improve their decision making without human intervention. This type of machine learning is particularly useful for solving complex problems that do not have a clear solution or where the optimal solution is not obvious. Applications of reinforcement learning can be found in many fields, including robotics, finance, gaming, and transportation.
Top 10 interview questions for reinforcement learning.
1. What is Markov Decision Process?
A Markov Decision Process is a model for decision making. It is used to create a model of the world that can predict the future based on past data. The model is called “Markov” because it assumes that the future depends only on the present, not on the past.
The Markov Decision Process was first introduced by Richard Bellman in 1957 and it has been used in many applications such as robotics and artificial intelligence.
2. What is the role of the Discount Factor in Reinforcement Learning?
The discount factor is an important concept in reinforcement learning. It is a measure of the importance of future rewards to current rewards.
The discount factor enters into the equation for calculating the expected future reward:
E[R] = Σ(Δt) * R(Δt) * δ (1-δ)
where Δt is the time step, R(Δt) is the reward at that time step, and δ is the discount factor.
3. Name some approaches or algorithms you know in to solve a problem in Reinforcement Learning.
In reinforcement learning, the agent is a computer program which is trying to learn how to behave in an environment. The agent’s goal is to maximize the total reward it receives by interacting with its environment.
There are many different approaches or algorithms that can be used in reinforcement learning. Some of these include:
Dynamic Programming (DP): When we know the whole model, DP makes it possible to iteratively improve policy with each iteration.
Monte-Carlo (MC)Methods: Artificial intelligence learn from episodes of raw experience without modelling the environmental dynamics in order to compute the observed mean return as an approximation of the expected return. One thing here you should consider is that the episodes must be complete, which means that they eventually terminate.
Temporal-Difference (TD) Learning: Unlike Monte-Carlo methods, TD learning is simplified and can be applied to any industry. However, it also adapts to incomplete episodes and learns to improve over time.
Policy Gradient methods: These methods use gradient descent on a policy gradient function to optimize the parameters of a policy.
Deep Deterministic Policy Gradient methods: These methods apply deep neural networks for estimating the gradients of policies and use them for estimating gradients of value functions.
Value Iteration: This method propagates values from states where they are known towards states where they are not known and updates their values using Bellman equations.
4. How to define States in Reinforcement Learning?
Reinforcement learning is a type of machine learning that uses trial and error to make predictions. Reinforcement learning is also known as “operant conditioning” or “machine learning” because it is similar to how children learn through rewards.
States are the key components of reinforcement learning, which means that they are the actions that an agent will take in response to its environment. States can be classified into three types: input states, output states, and transition states. Input states are what the agent sees in its environment; output states are what the agent does; and transition states are the changes from input to output or from output to input.
The three types of state can be further divided into two categories: discrete and continuous. Discrete state is one where there is only one possible outcome for each action taken , such as the agent pressing one of two buttons consecutively. Continuous state is one where there are many possible outcomes for each action, such as the agent moving to a random point on the screen. State functions are mathematical functions that define how an agent’s environment changes in response to its actions.
5. What is the difference between a Reward and a Value for a given State?
There are two main types of reinforcement learning:
Reward-based learning is when a system learns to perform an action that leads to a reward.
Reward-based learning is a method that some AI systems use to teach themselves. It can be used for training robots or teaching human children new skills. This approach uses rewards and punishments to determine how much time a system should spend learning a given task.
Value-based learning is when a system learns to perform an action that leads to a value.
Value-based learning is when a system learns to perform an action that leads to a value. Value-based learning has been successfully implemented in both human and robotic systems. In order to learn something, the learner has to have some sort of reward for the action. So, if there is no reward for the learned behavior, then the learner will not be able to learn that particular task.
Reward-based learning is more common in games, where the player can earn points, coins, or unlockables. A study conducted in 2003 found that games that were non-reward-based (such as puzzles and learning) had low retention rates.
Value-based learning is more common in business applications where the goal may be to increase sales or improve customer retention. rates. There are several benefits to using value-based learning in business applications: The use of value-based learning can increase productivity through increased employee engagement and “the idea that learning is a source of personal fulfilment and professional advancement.” This can be seen through the increase in job satisfaction, higher retention rates, and lower turnover for employees.
6. How do you know when a Q-Learning Algorithm converges?
Q-Learning algorithm is a reinforcement learning algorithm that learns to play video games by exploring the game world. The algorithm is designed to learn by trial and error.
When a Q-Learning Algorithm converges, it will start playing the game without any mistakes. It will also be able to beat its previous best score without getting stuck in a bad state.
Q-learning algorithms have been used in robotics, video games, and other applications where they need to explore their environment while learning from their experiences.
7. What are the steps involved in a typical Reinforcement Learning algorithm?
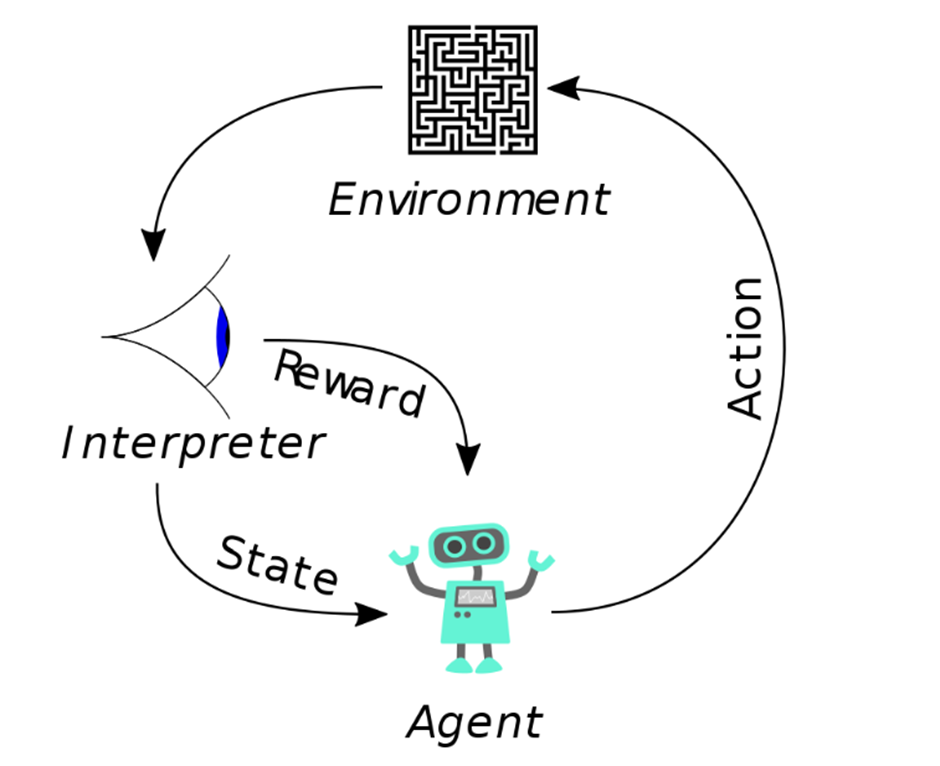
Reinforcement learning is an artificial intelligence technique that uses trial and error to maximize the long-term goal of a system.
This process starts with an agent (the machine) receiving a reward signal. The agent then takes some actions, which are the inputs to the algorithm. After each action, the agent receives a new reward signal. The next time, it will try to take different actions in order to get better rewards.
The following steps are involved in reinforcement learning:
1) The agent receives a reward signal from its environment (e.g., from an input).
2) The agent takes some actions based on previous experiences and generates new rewards signals.
3) The agent gets updated with new rewards signals after each action taken by it and learns more about what works best for it.
8. What is the difference between Off-Policy and On-Policy Learning?
Off-Policy Learning: Off-policy learning is when the agent does not know what the correct answer is, so it will make random decisions. This type of learning has no guarantee for success because there is no way to tell if an agent will make the correct decision or not.
On-Policy Learning: On-policy learning is when an agent knows what the correct answer is, so it will always choose that option before making a decision. This type of learning has more success because there’s less chance for failure and more opportunities for reward.
9. What do the Alpha and Gamma parameters represent in Q Learning?
In reinforcement learning, the Alpha parameter is used to represent the discount rate and the Gamma parameter represents the action selection.
Alpha: The alpha parameter is used to represent how much a learner discounts future rewards when compared with current rewards. This value determines how quickly a learner learns new behavior.
Gamma: The gamma parameter is used to represent how much a learner selects an action when compared with all other actions. This value determines how many choices are available for an agent before it selects one.
10. What type of Neural Networks do Deep Reinforcement Learning use?
Deep reinforcement learning (DRL) is a type of reinforcement learning that uses deep neural networks to learn the value function. DRL has been shown to be more effective than traditional methods and can be used for tasks such as playing games, driving cars, and making an autonomous robot.
