
Day 5: Part-of-Speech Tagging and Named Entity Recognition
Welcome back peeps as we have already discussed about the tokenization and stop words in our last article so, in this day 5 of Natural Language Processing (NLP) journey! In this blog we will be exploring two important techniques for analyzing text:
- Part-of-Speech (POS) tagging
- Named Entity Recognition (NER)
1 – Part-of-Speech (POS) tagging is the process of labelling each word in a text corpus with its corresponding part of speech, such as noun, verb, adjective, adverb, etc. This can be useful for identifying the structure and meaning of a sentence, as well as for tasks like sentiment analysis and text classification.
Let’s look at the example of POS tagging using Python’s Natural Language Toolkit (NLTK):

In this example, we first tokenize the text into individual words using NLTK’s word_tokenize function and then we applied POS tagging using the pos_tag function, which returns a list of tuple, with each tuple representing a word and its corresponding part of speech tag.
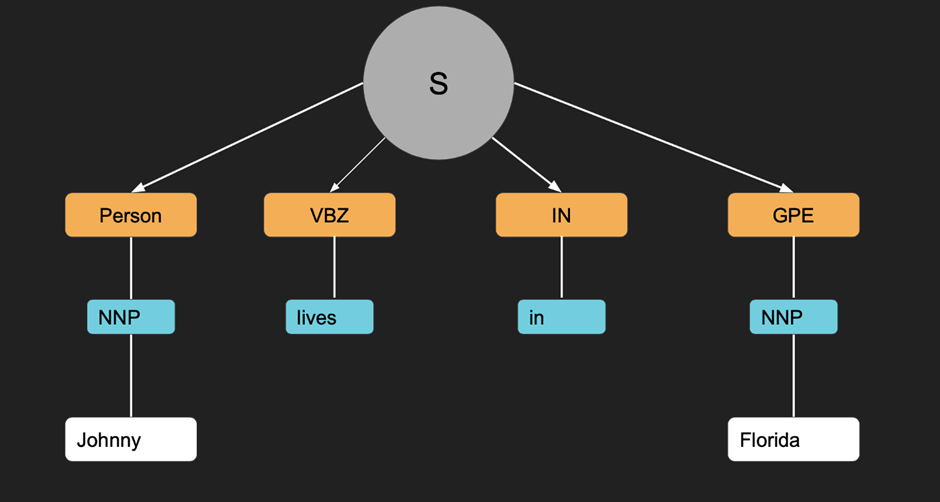
2 – Named Entity Recognition (NER) is the process of identifying and classifying the entities in text, such as people, organization, locations, and dates. This can be useful for tasks like information extraction and question answering.
Let’s look at the example of NER using NLTK:

In this example, we first tokenize the text and then we applied POS tagging using NLTK’s pos_tag function. We then applied NER using the ne_chunk function, which returns a tree structure that labels named entities in the text. The output shows that “John Smith” is identified as a person, “Nomidl Corporation” is identified as an organization, and “New York City” is identified as a location.
Both POS tagging and NER can be powerful tools for analyzing text, and can be used in a wide range of NLP applications. By understanding the structure and meaning of text, we can gain valuable insights and make more informed decisions.
In conclusion, Part-of-Speech (POS) tagging and Named Entity Recognition (NER) are important techniques in Natural Language Processing that allow us to analyze and understand the structure and meaning of text. With POS tagging, we can identify the different parts of speech in a sentence, which can be useful for tasks like sentiment analysis and text classification. Meanwhile, NER helps us to identify and classify named entities in text, such as people, organizations, locations, and dates. This can be useful for information extraction and question answering.
I hope you liked this article, if you have any question let me know in the comment.
