
Day 8: Text Classification with Naïve Bayes
Text Classification is a popular technique used in Natural Language Processing to categorize text documents into predefined categories. Naïve Bayes is a commonly used algorithm for text classification, as it is simple and efficient. In this blog post, we will look at the process of building a Text Classification model using Naïve Bayes, step-by-step. We will start by importing necessary libraries, loading and exploring the data, then creating feature and label sets. We will split the data into training and testing sets, and train a Naïve Bayes classifier on the training data. We will evaluate the performance of the model by making predictions on the testing data and generating a confusion matrix, classification report, and accuracy score.
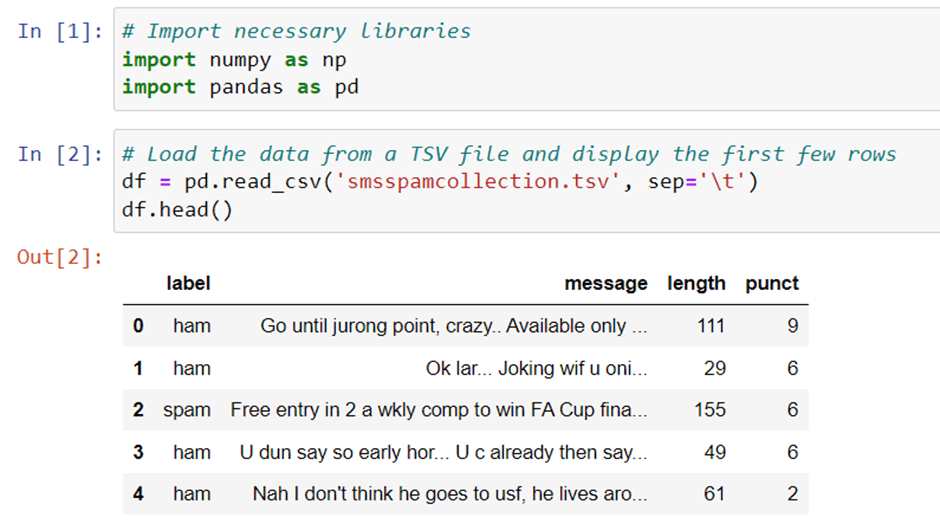
Firstly, necessary libraries (numpy and pandas) are imported. Then, the dataset is loaded into a DataFrame from a TSV file and the first five rows of the DataFrame are displayed.
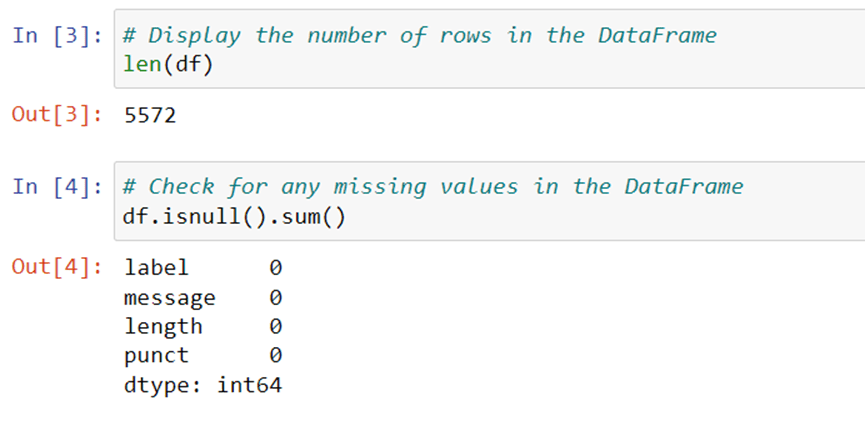
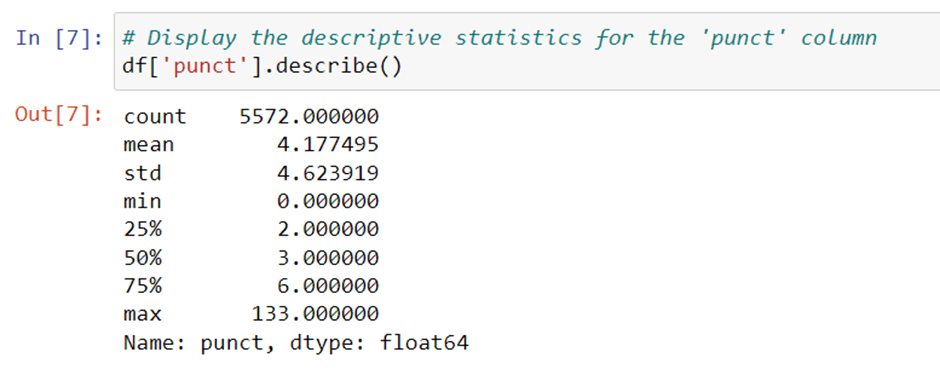
Next, we check the length of the dataset and for any missing values in the DataFrame by applying the isnull() and sum() methods, respectively. We also display the unique values in the ‘message’ column by applying the unique() method and the count of each unique value in the ‘message’ column by applying the value_counts() method. The descriptive statistics for the ‘punct’ column are displayed using the describe() method.

We plot a histogram of the ‘punct’ column separated by the ‘label’ column using the hist() method of the matplotlib library. A message is then printed to indicate that the results are not good because there seem to be no values where one would pick spam over ham.


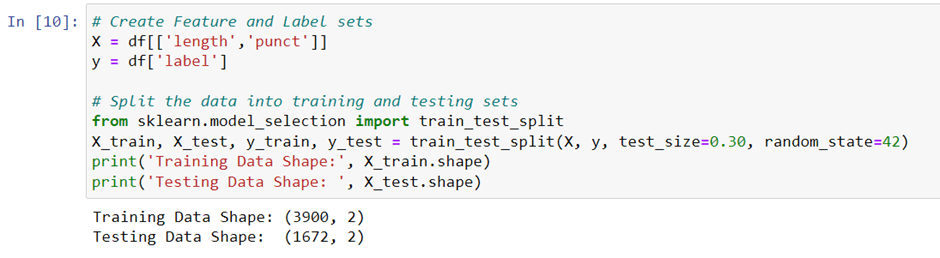
We create feature and label sets, X and y, respectively. We split the data into training and testing sets using the train_test_split() method of the scikit-learn library. The shapes of the training and testing data sets are also displayed.
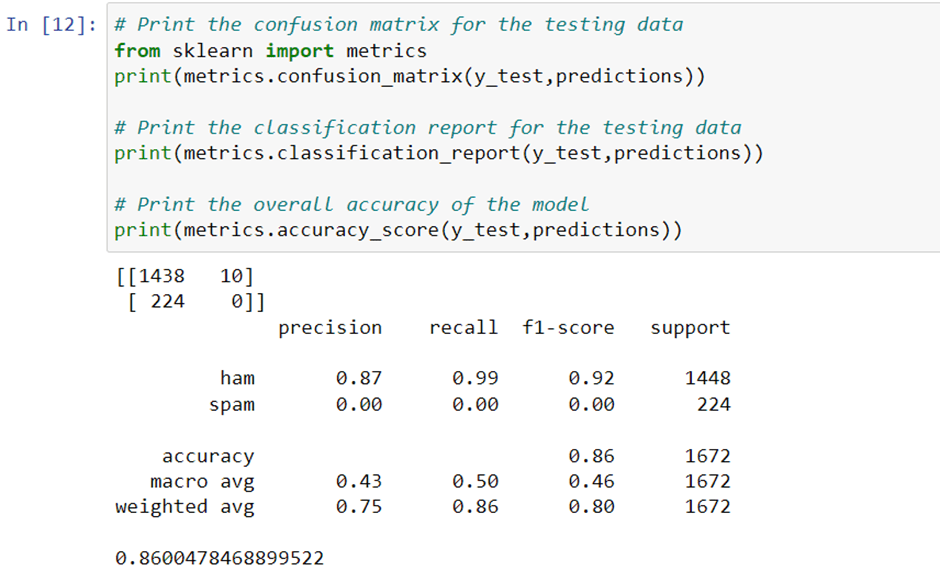
We train a Naive Bayes classifier on the training data using the MultinomialNB() method of the scikit-learn library. We make predictions on the testing data using the trained classifier and print the confusion matrix for the testing data, the classification report for the testing data, and the overall accuracy of the model using the confusion_matrix(), classification_report(), and accuracy_score() methods of the scikit-learn library, respectively.

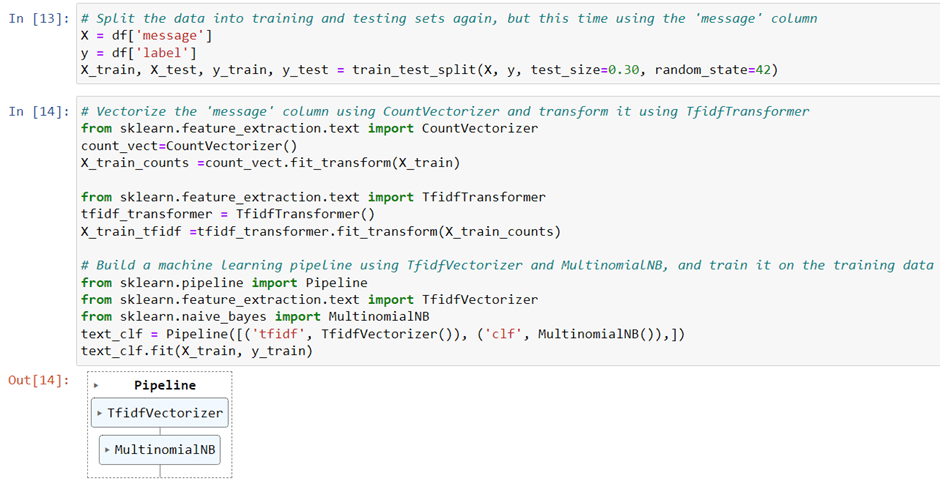
Then, we split the data into training and testing sets again, but this time using the ‘message’ column. We vectorize the ‘message’ column using CountVectorizer() and transform it using TfidfTransformer(). We build a machine learning pipeline using TfidfVectorizer() and MultinomialNB(), and train it on the training data. We make predictions on the testing data using the trained pipeline and evaluate the performance of the model using the confusion_matrix(), classification_report(), and accuracy_score() methods of the scikit-learn library.
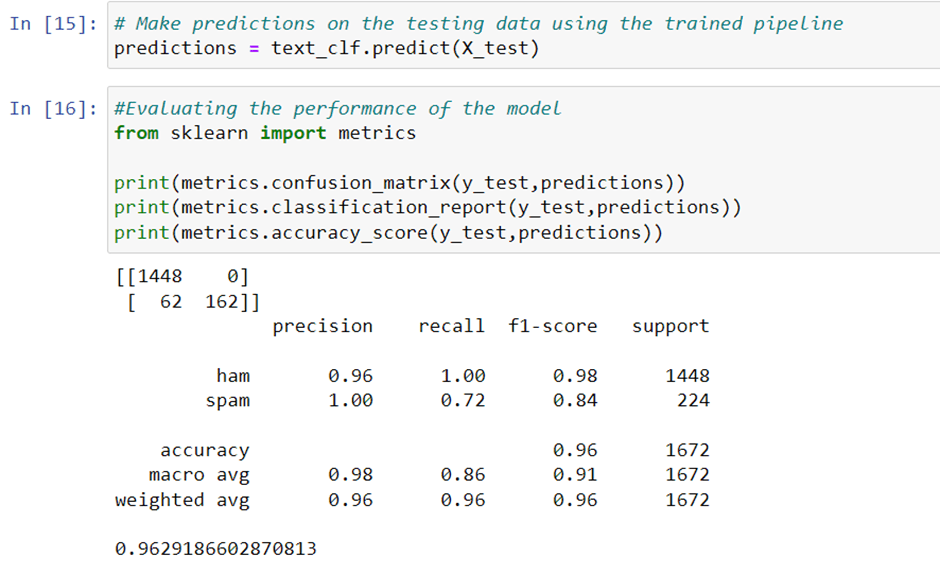
In conclusion, this code demonstrates how to build a spam detection model using machine learning by applying various methods and techniques of the scikit-learn and matplotlib libraries.
