
Tokenization in NLP: Breaking Language into Meaningful Words
Tokenization is a fundamental concept in Natural Language Processing (NLP) that involves breaking down text into smaller tokens. Whether you’ve heard of tokenization before or not, this article will help you get the clear and concise explanation.
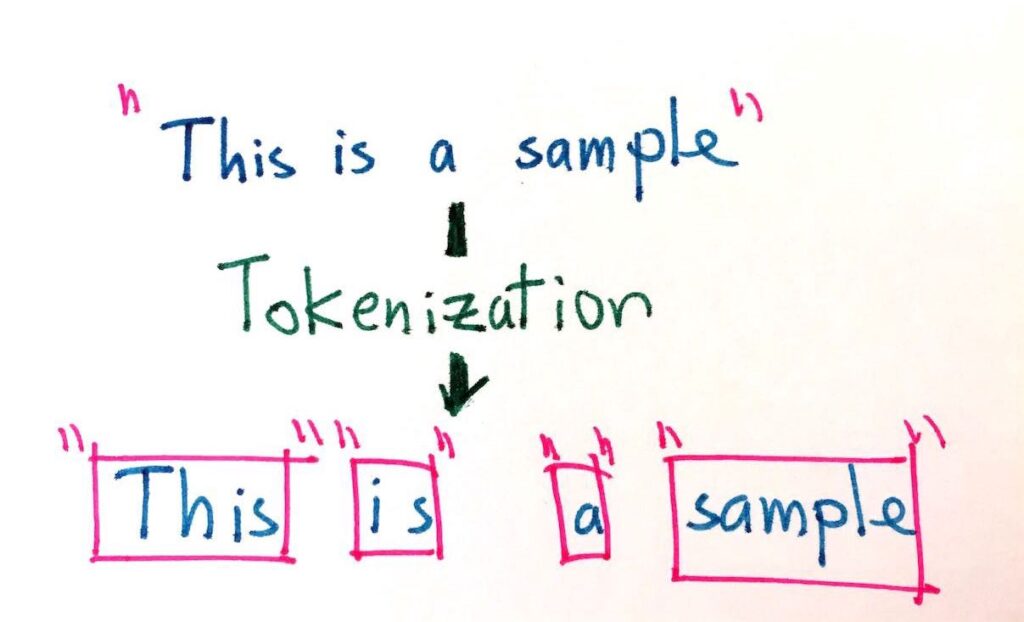
What is Tokenization?
Tokenization is the process of dividing a given text, such as a document, paragraph, or sentence, into individual words or units called tokens. We use these tokens as the building blocks for further analysis and processing in NLP tasks.
Understanding Tokenization
Let’s look at a simple example to explain the concept of tokenization. Imagine you have a document that contains several paragraphs, sentences and words. For simplicity, we will focus on one paragraph. The purpose of a token is to break this part into its constituent parts, where each word represents a token. This process of dividing text into characters is called tokenization.
Tokenization in Practice
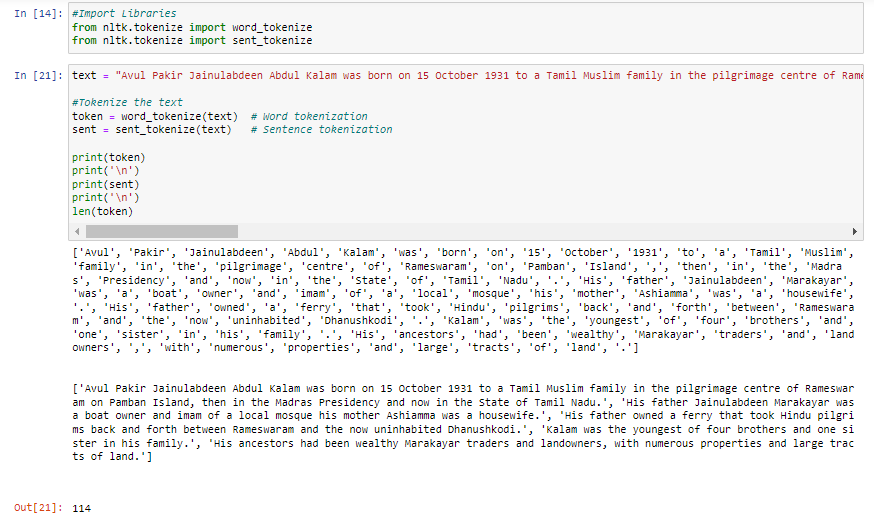
There are various tools and libraries available for tokenization in NLP. One commonly used tool is the nltk.word_tokenize() function, which effectively splits a sentence into individual words or characters. Using this feature, we can easily split sentences into component tags for further analysis and processing.
Also, if we need to segment the text into sentences and determine the length of each sentence, we can use the nltk.sent_tokenize() function to tokenize the sentences and use the len() function to calculate the length of each sentence.
Let’s look at the example:
Conclusion
Tokenization plays a important role in NLP by breaking down text into meaningful units or tokens. These tokens are essential for various NLP tasks, such as text classification, sentiment analysis, and machine translation. By using tools like nltk.word_tokenize() and nltk.sent_tokenize(), we can effectively perform tokenization at both the word and sentence levels.
FAQs
1. What is tokenization in NLP?
Tokenization is the process of breaking a long piece of text into smaller parts, called tokens. These tokens are usually words or sentences. It’s one of the first steps in NLP and helps machines understand and work with human language more effectively.
2. Why is tokenization important in NLP?
Without tokenization, computers would struggle to make sense of large blocks of text. By breaking text into words or sentences, it becomes easier to analyze language, understand meaning, and perform tasks like translation or sentiment detection.
3. Can you give a simple example of tokenization?
Sure! If you have a sentence like “I love learning NLP,” tokenization would split it into:["I", "love", "learning", "NLP"]
Each word becomes a token, making it easier for a program to analyze them individually.
4. What tools are used for tokenization in Python?
A popular Python library for NLP is NLTK. It offers functions like word_tokenize() to split text into words, and sent_tokenize() to split text into sentences. These tools are simple to use and very effective.
5. Is tokenization only useful for splitting words?
Not at all. Tokenization can be done at multiple levels words, sentences, or even characters. Depending on the task, you might tokenize differently. For example, character-level tokenization is useful in spell-checking or autocorrect systems.
