
5 Tips for Efficient Data Manipulation with Python
Pandas is a powerful tool for data manipulation, but it can be challenging to use efficiently. In this blog post, we will provide you with 5 tips to help you manipulate data more efficiently using Pandas. These tips will help you save time and produce more accurate results.
Tip 1:Use vectorized operations
One of the most common mistake beginners make while working with Pandas is using loops to iterate over each row of a dataframe. Instead, you can use vectorized functions which are optimized for speed and efficiency. Let’s see the example, to multiply all the values in a column by 2, you can simply write:
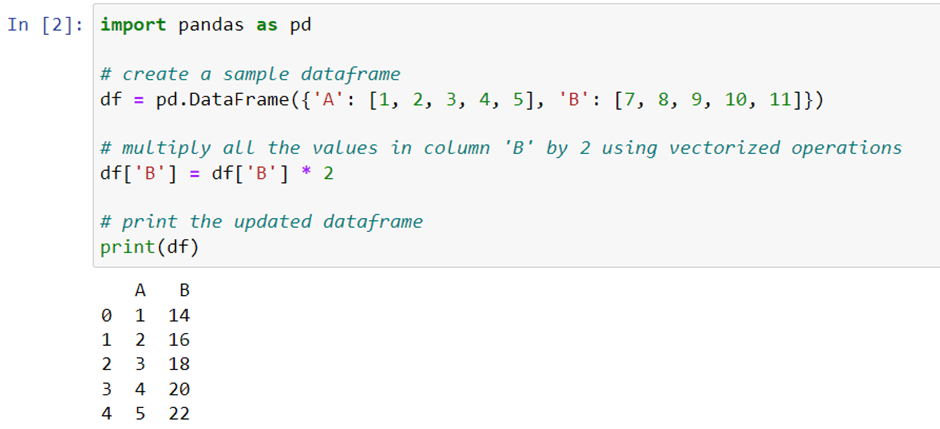
This will perform the operation on the entire column at once.
Tip 2: Avoid chained indexing
Chained indexing is when you chain indexing operations together. For example, instead of using df.loc[row_index, column_index], you might write df[row_index][column_index]. However, this can lead to unexpected results and errors. To avoid this, you can use loc or iloc instead of chained indexing.
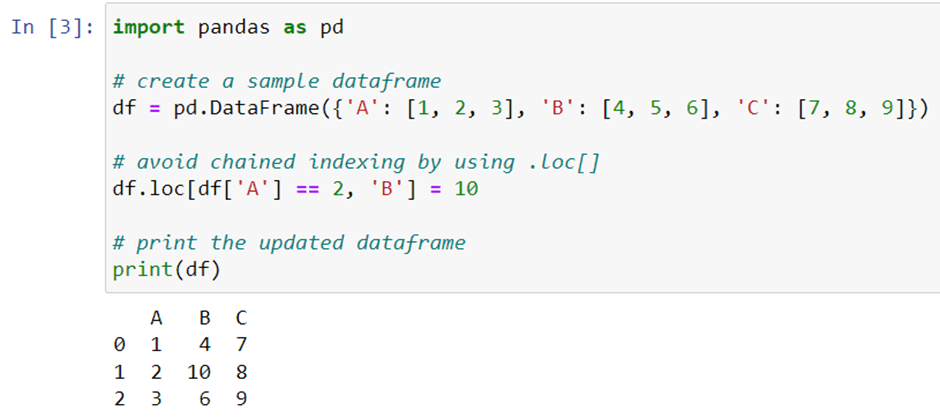
As you can see, instead of using chained indexing (i.e. df[df[‘A’] == 2][‘B’]), we use .loc[] to avoid ambiguity and improve code readability.
Tip 3: Use apply instead of loops
Another common mistake is using loops to perform calculations on each row or column of a dataframe. Instead, you can use the apply method which applies a function to each row or column of a dataframe. For example, to calculate the square root of each value in a column, you can write:
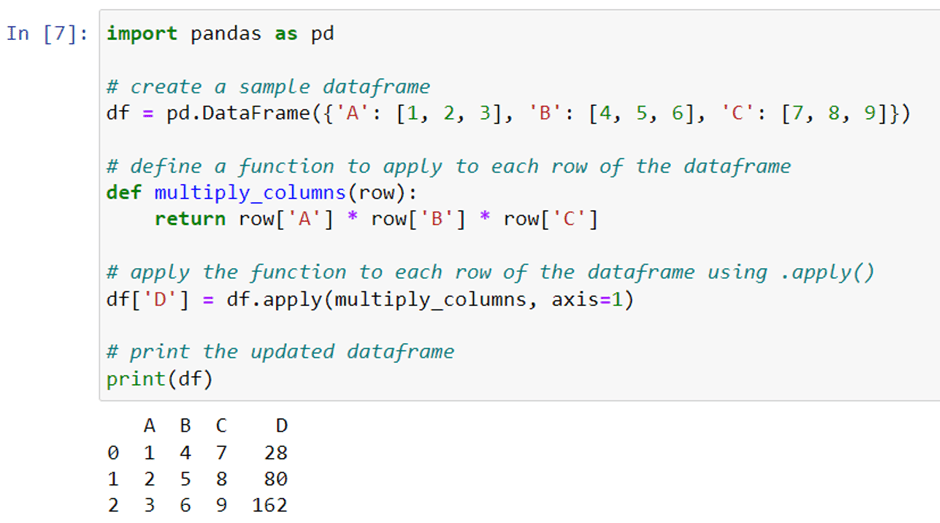
As you can see, we define a function to apply to each row of the dataframe, and then use .apply() to apply the function to each row. This is more efficient than using a loop to iterate over each row, and makes the code more concise and readable.
Tip 4: Use groupby for aggregations
If you need to perform aggregations on your data, such as summing or averaging values, use the groupby method. This method groups the data based on one or more columns and then applies the aggregation function to each group. For example, to calculate the mean salary of each department in a dataframe, you can write:
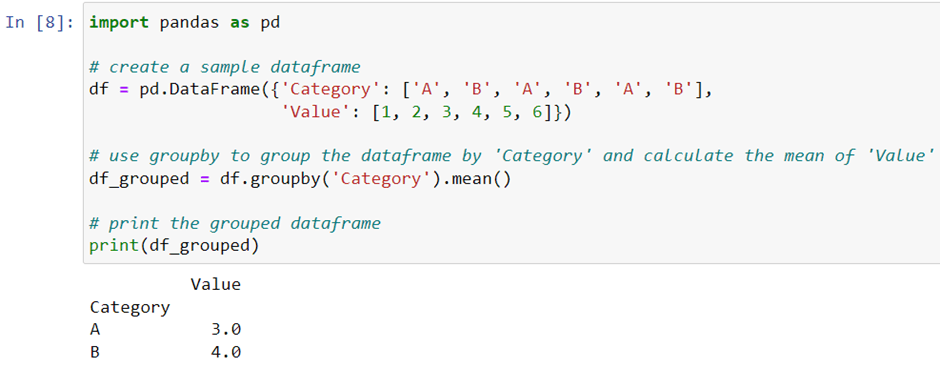
As you can see, we use groupby to group the dataframe by the ‘Category’ column, and then apply the .mean() method to calculate the mean of the ‘Value’ column for each group. This is more efficient than using a loop to iterate over each group, and makes the code more concise and readable.
Tip 5: Use merge for joining dataframes
If you need to join two or more dataframes, use the merge method instead of concatenating them. Merge allows you to join dataframes on one or more columns, making it easier to combine data from different sources. For example, to join two dataframes based on a common column, you can write:
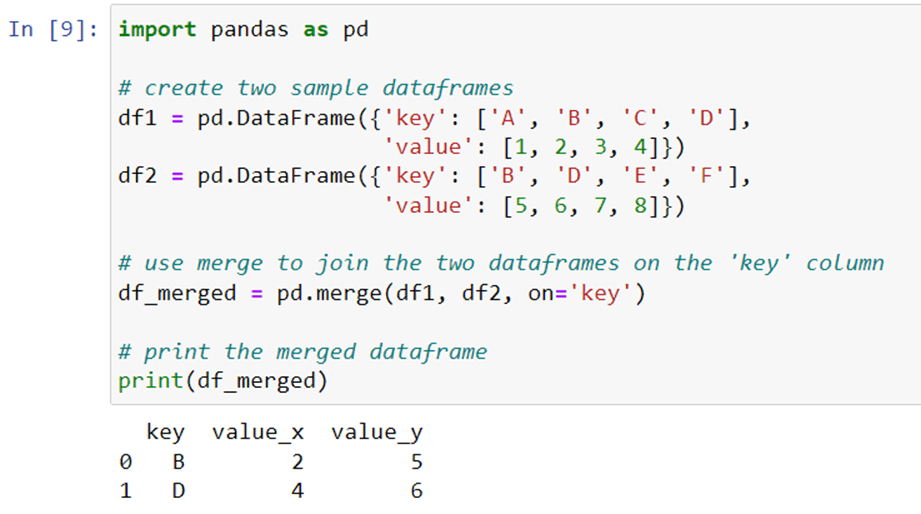
As you can see, we use merge to join the two dataframes on the ‘key’ column, which is common to both dataframes. This is more efficient than using a loop to iterate over each row of both dataframes and checking for matching keys, and makes the code more concise and readable.
Conclusion
By following these 5 tips, you can make your data manipulation tasks more efficient and effective. Remember to use vectorized operations, avoid chained indexing, use apply instead of loops, use groupby for aggregations, and use merge for joining dataframes. With these tips, you can save time, avoid errors, and produce more accurate results. I hope you liked this article, let me know if you have any question.
